Python并行编程
- 本书说明
- 1 认识并行计算和Python
- 1.1 介绍
- 1.2 并行计算的内存架构
- 1.3 内存管理
- 1.4 并行编程模型
- 1.5 如何设计一个并行程序
- 1.6 如何评估并行程序的性能
- 1.7 介绍Python
- 1.8 并行世界的Python
- 1.9 介绍线程和进程
- 1.10 开始在Python中使用进程
- 1.11 开始在Python中使用线程
- 2 基于线程的并行
- 2.1 介绍
- 2.2 使用Python的线程模块
- 2.3 如何定义一个线程
- 2.4 如何确定当前的线程
- 2.5 如何实现一个线程
- 2.6 使用Lock进行线程同步
- 2.7 使用RLock进行线程同步
- 2.8 使用信号量进行线程同步
- 2.9 使用条件进行线程同步
- 2.10 使用事件进行线程同步
- 2.11 使用with语法
- 2.12 使用 queue 进行线程通信
- 2.13 评估多线程应用的性能
- 3 基于进程的并行
- 3.1 介绍
- 3.2 如何产生一个进程
- 3.3 如何为一个进程命名
- 3.4 如何在后台运行一个进程
- 3.5 如何杀掉一个进程
- 3.6 如何在子类中使用进程
- 3.7 如何在进程之间交换对象
- 3.8 进程如何同步
- 3.9 如何在进程之间管理状态
- 3.10 如何使用进程池
- 3.11 使用Python的mpi4py模块
- 3.12 点对点通讯
- 3.13 避免死锁问题
- 3.14 集体通讯:使用broadcast通讯
- 3.15 集体通讯:使用scatter通讯
- 3.16 集体通讯:使用gather通讯
- 3.17 使用Alltoall通讯
- 3.18 简化操作
- 3.19 如何优化通讯
- 4 异步编程
- 4.1 介绍
- 4.2 使用Python的 concurrent.futures 模块
- 4.3 使用Asyncio管理事件循环
- 4.4 使用Asyncio管理协程
- 4.5 使用Asyncio控制任务
- 4.6 使用Asyncio和Futures
- 5 分布式Python编程
- 5.1 介绍
- 5.2 使用Celery实现分布式任务
- 5.3 如何使用Celery创建任务
- 5.4 使用SCOOP进行科学计算
- 5.5 通过 SCOOP 使用 map 函数
- 5.6 使用Pyro4进行远程方法调用
- 5.7 使用 Pyro4 链接对象
- 5.8 使用Pyro4部署客户端-服务器应用
- 5.9 PyCSP和通信顺序进程
- 5.10 使用Disco进行MapReduce
- 5.11 使用RPyC远程调用
- 6 Python GPU编程
介绍
图形处理器是一种擅长渲染多边形单元的图像的电子元件。虽然GPU原先的设计目的是渲染图像,但随着不断优化,GPU已经变得越来越复杂,在实时渲染和离线渲染方面的效率也更高。除此之外,GPU也逐渐开始应用在科学计算领域。GPU 的特点是架构高度并行,所以擅长快速处理超大数据集。随着近几年硬件性能的快速提升,以及它的可编程性,GPU 很快引起了学术界的注意。GPU 不再仅仅用于图形渲染领域,人们开始探索它在其他方面的可能性。传统的 GPU 是固定的功能设备,渲染流程是固定于硬件上的。这就限制了图形程序员去使用不同的、更高效、质量更高的渲染算法。所以,现代 GPU 都是建立在百万个轻量级并行核心上的,可以使用 shaders 来编程定义图形渲染。这在图形渲染和游戏方面是划时代的进步。有了这么多可以编程的核心,GPU 厂商逐渐开始开发并行编程模型。每个 GPU 由多个流式处理器(Streaming Multiprocessor, SM)组成,它代表并行的第一层逻辑级别,每一个 SM 都是并行独立、互不干扰地工作。
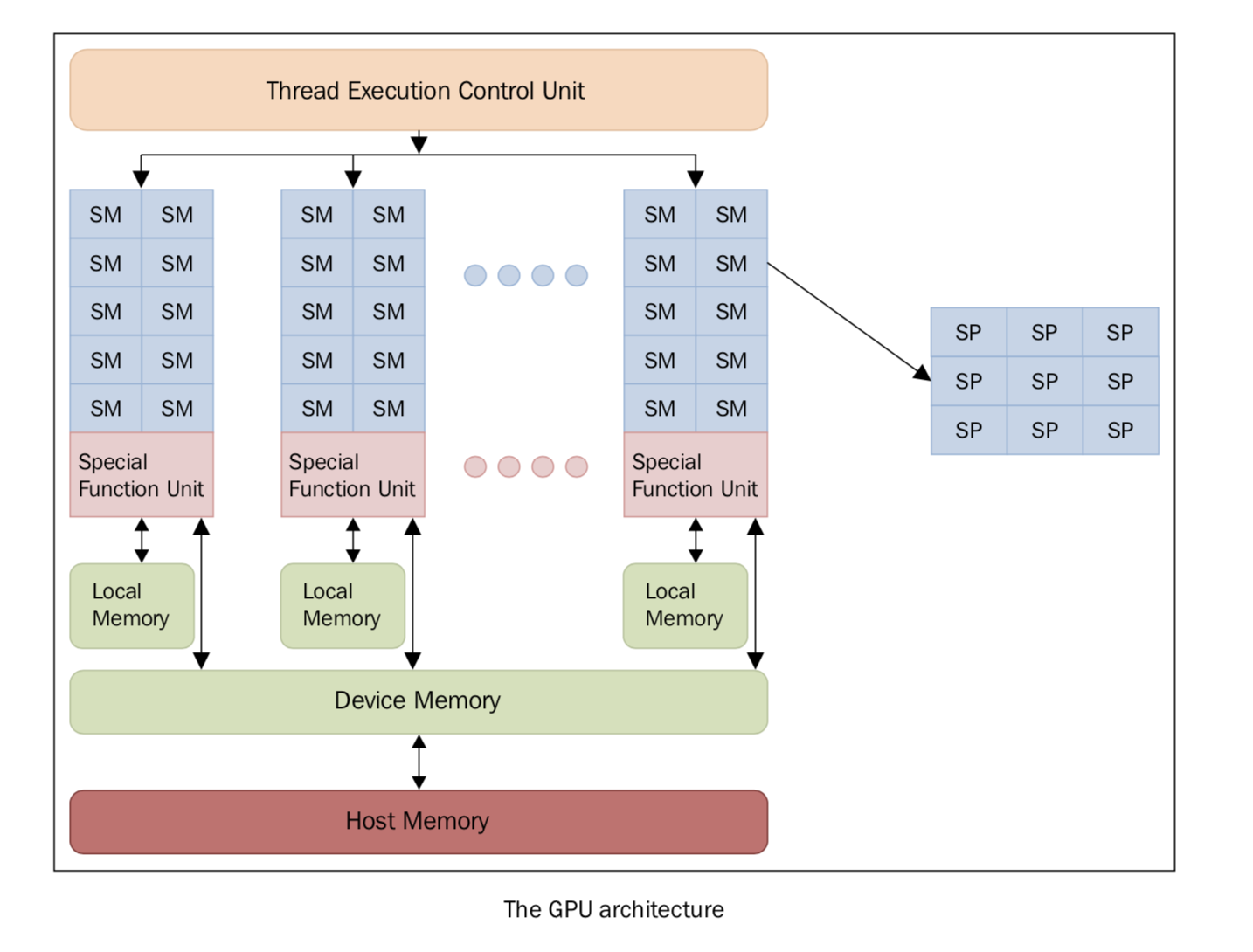
每个 SM 又被分成一组流处理器(Stream Processors, SP),每一个 SP 都有一个可以执行的核心,可以运行一个线程。SP 是执行逻辑的最小单位,表示更精细的并行度。SM和SP的概念本质上是结构性的,但这可以概述 GPU 的 SP 的组织逻辑,即以特定执行模式为特征的逻辑单元组合在一起。一组中所有核心同时运行相同的指令,属于我们在本书第一章中描述的单指令多数据(SIMD)模型。
每一个 SM 都有多个寄存器,寄存器可以被认为是一小块读写速度很快的、临时的、本地的(不同核心之间无法共享)的内存。每个核心可以使用这些寄存器来存储常用的值。有一个学科叫做图形处理单元上的通用计算(general-purpose computing on graphics processing units, GP-GPU),致力于研究 GPU 的高速并行计算能力。之前介绍过,GPU 和传统的处理器架构很不同,所以它们也面临不同性质的问题,需要不同的编程技术。GPU 最亮眼的特点是有大量的核心,我们可以同时执行很多个线程计算单元,它们同时执行相同的操作。想象这样一个场景,你需要把数据分成很多小的部分,然后在这些小的部分上执行相同的操作,这时候这种计算模式就效率很高。相反,如果你的操作必须严格按照一定的顺序来执行,这种架构的发挥余地就不大了。在其他不能将计算平均地分成很多小的部分的情况,也不适用于这种架构。GPU 的这种编程范式被称为流计算(Stream Processing), 因为数据可以看做是一个巨大的数据流,相同的操作不断在这个流上面操作。
目前,能发挥 GPU 的这种计算能力最好的解决方案是 CUDA 和 OpenCL 这两个库。下面几节中,我们将用 Python 来展示这些库的用法。