Kubernetes 核心依赖组件 ETCD 的监控详解
写在前面
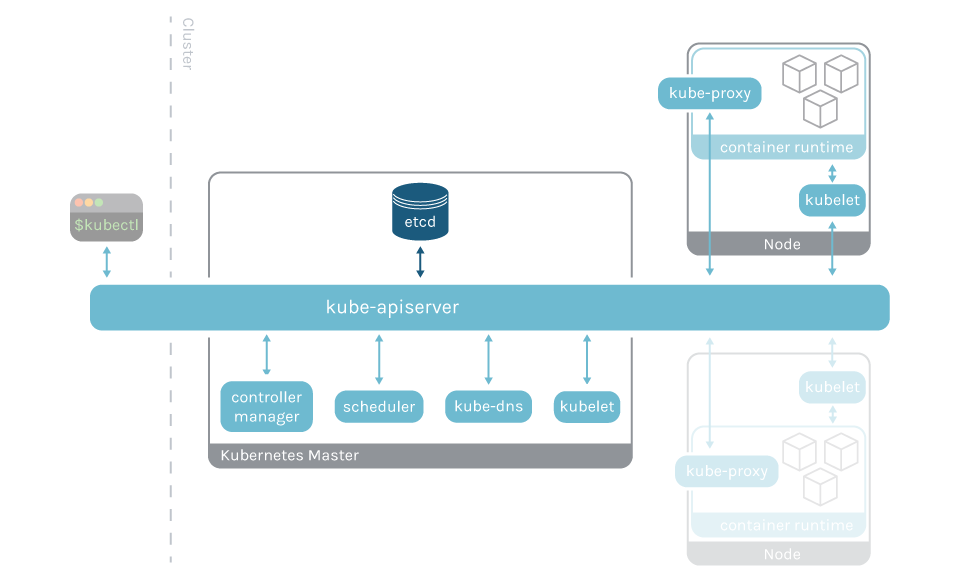
ETCD 是 Kubernetes 控制面的重要组件和依赖,Kubernetes 的各类信息都存储在 ETCD 中,所以监控 ETCD 就显得尤为重要。ETCD 在 Kubernetes 中的架构角色如下(只与 APIServer 交互):
[
ETCD 是一个类似 Zookeeper 的产品,通常由多个节点组成集群,节点之间使用 raft 协议保证一致性。ETCD 具有以下特点:
- 每个节点都有一个角色状态,Follower、Candidate、Leader
- 如果 Follower 找不到当前 Leader 节点的时候,就会变成 Candidate
- 选举系统会从 Candidate 中选出 Leader
- 所有的写操作都通过 Leader 进行
- 一旦 Leader 从大多数 Follower 拿到 ack,该写操作就被认为是“已提交”状态
- 只要大多数节点存活,整个 ETCD 就是存活的,个别节点挂掉不影响整个集群的可用性
- ETCD 使用 restful 风格的 HTTP API 来操作,这使得 ETCD 的使用非常方便,这也是 ETCD 流行的一个关键因素
读取 /metrics 接口
ETCD 这么云原生的组件,显然是内置支持了 /metrics 接口的,不过 ETCD 很讲求安全性,默认的 2379 端口的访问是要用证书的,我来测试一下先:
[root@tt-fc-dev01.nj ~]# curl -k https://localhost:2379/metrics
curl: (35) error:14094412:SSL routines:ssl3_read_bytes:sslv3 alert bad certificate
[root@tt-fc-dev01.nj ~]# ls /etc/kubernetes/pki/etcd
ca.crt ca.key healthcheck-client.crt healthcheck-client.key peer.crt peer.key server.crt server.key
[root@tt-fc-dev01.nj ~]# curl -s --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key https://localhost:2379/metrics | head -n 6
# HELP etcd_cluster_version Which version is running. 1 for 'cluster_version' label with current cluster version
# TYPE etcd_cluster_version gauge
etcd_cluster_version{cluster_version="3.5"} 1
# HELP etcd_debugging_auth_revision The current revision of auth store.
# TYPE etcd_debugging_auth_revision gauge
etcd_debugging_auth_revision 1使用 kubeadm 安装的 Kubernetes 集群,相关证书是在 /etc/kubernetes/pki/etcd 目录下,为 curl 命令指定相关证书,是可以访问的通的。后面使用 Categraf 的 prometheus 插件直接采集相关数据即可。
不过指标数据实在没必要做这么强的安全管控,整的挺麻烦,实际上,ETCD 也确实提供了另一个端口来获取指标数据,无需走这套证书认证机制。我们看一下ETCD的启动命令,在Kubernetes体系中,直接导出 ETCD 的 Pod 的 yaml 信息即可:
kubectl get pod -n kube-system etcd-10.206.0.16 -o yaml
上例中 etcd-10.206.0.16 是我的 ETCD 的 podname,你的可能是别的名字,自行替换即可。输出的内容中可以看到 ETCD 的启动命令:
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://10.206.0.16:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --initial-advertise-peer-urls=https://10.206.0.16:2380
- --initial-cluster=10.206.0.16=https://10.206.0.16:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://10.206.0.16:2379
- --listen-metrics-urls=http://0.0.0.0:2381
- --listen-peer-urls=https://10.206.0.16:2380
- --name=10.206.0.16
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: registry.aliyuncs.com/google_containers/etcd:3.5.1-0注意 --listen-metrics-urls=http://0.0.0.0:2381 这一行,这实际就是指定了 2381 这个端口可以直接获取 metrics 数据,我们来测试一下:
[root@tt-fc-dev01.nj ~]# curl -s localhost:2381/metrics | head -n 6
# HELP etcd_cluster_version Which version is running. 1 for 'cluster_version' label with current cluster version
# TYPE etcd_cluster_version gauge
etcd_cluster_version{cluster_version="3.5"} 1
# HELP etcd_debugging_auth_revision The current revision of auth store.
# TYPE etcd_debugging_auth_revision gauge
etcd_debugging_auth_revision 1挺好,好使,后面我们就直接通过这个接口来获取数据即可。
更多监控相关的知识、SRE相关的知识,欢迎加入我的[「知识星球」] 学习
数据采集
ETCD 的数据采集通常使用 3 种方式:
- 使用 ETCD 所在宿主的 agent 直接来采集,因为 ETCD 是个静态 Pod,采用的 hostNetwork,所以 agent 直接连上去采集即可
- 把采集器和 ETCD 做成 sidecar 的模式,ETCD 的使用其实已经越来越广泛,不只是给 Kubernetes 使用,很多业务也在使用,在 Kubernetes 里创建和管理 ETCD 也是很常见的做法,sidecar 这种模式非常干净,随着 ETCD 创建而创建,随着其销毁而销毁,省事
- 使用服务发现机制,在中心端部署采集器,就像之前的文章中介绍的 APIServer、Controller-manager、Scheduler 等的做法,使用 Prometheus agent mode 采集监控数据,当然,这种方式的话需要有对应的 etcd endpoint,你可以自行检查一下
kubectl get endpoints -n kube-system,如果没有,创建一下即可:
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: etcd
labels:
k8s-app: etcd
spec:
selector:
component: etcd
type: ClusterIP
clusterIP: None
ports:
- name: http
port: 2381
targetPort: 2381
protocol: TCP如果走的是 prometheus agent mode 的方式来采集,注意抓取规则部分和之前讲的组件就不同了,不用走 https 了:
- job_name: 'etcd'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;etcd;http仪表盘
之前孔飞老师整理过 ETCD 的 Dashboard,地址在https://github.com/flashcatcloud/categraf/blob/main/k8s/etcd-dash.json,可以直接导入夜莺使用。
关键指标
ETCD 也采集了不少指标,其中一些关键指标的含义如下,感谢孔飞老师整理:
# HELP etcd_server_is_leader Whether or not this member is a leader. 1 if is, 0 otherwise.
# TYPE etcd_server_is_leader gauge
etcd leader 表示 ,1 leader 0 learner
# HELP etcd_server_health_success The total number of successful health checks
# TYPE etcd_server_health_success counter
etcd server 健康检查成功次数
# HELP etcd_server_health_failures The total number of failed health checks
# TYPE etcd_server_health_failures counter
etcd server 健康检查失败次数
# HELP etcd_disk_defrag_inflight Whether or not defrag is active on the member. 1 means active, 0 means not.
# TYPE etcd_disk_defrag_inflight gauge
是否启动数据压缩,1表示压缩,0表示没有启动压缩
# HELP etcd_server_snapshot_apply_in_progress_total 1 if the server is applying the incoming snapshot. 0 if none.
# TYPE etcd_server_snapshot_apply_in_progress_total gauge
是否再快照中,1 快照中,0 没有
# HELP etcd_server_leader_changes_seen_total The number of leader changes seen.
# TYPE etcd_server_leader_changes_seen_total counter
集群leader切换的次数
# HELP grpc_server_handled_total Total number of RPCs completed on the server, regardless of success or failure.
# TYPE grpc_server_handled_total counter
grpc 调用总数
# HELP etcd_disk_wal_fsync_duration_seconds The latency distributions of fsync called by WAL.
# TYPE etcd_disk_wal_fsync_duration_seconds histogram
etcd wal同步耗时
# HELP etcd_server_proposals_failed_total The total number of failed proposals seen.
# TYPE etcd_server_proposals_failed_total counter
etcd proposal(提议)失败总次数(proposal就是完成raft协议的一次请求)
# HELP etcd_server_proposals_pending The current number of pending proposals to commit.
# TYPE etcd_server_proposals_pending gauge
etcd proposal(提议)pending总次数(proposal就是完成raft协议的一次请求)
# HELP etcd_server_read_indexes_failed_total The total number of failed read indexes seen.
# TYPE etcd_server_read_indexes_failed_total counter
读取索引失败的次数统计(v3索引为所有key都建了索引,索引是为了加快range操作)
# HELP etcd_server_slow_read_indexes_total The total number of pending read indexes not in sync with leader's or timed out read index requests.
# TYPE etcd_server_slow_read_indexes_total counter
读取到过期索引或者读取超时的次数
# HELP etcd_server_quota_backend_bytes Current backend storage quota size in bytes.
# TYPE etcd_server_quota_backend_bytes gauge
当前后端的存储quota(db大小的上限)
通过参数quota-backend-bytes调整大小,默认2G,官方建议不超过8G
# HELP etcd_mvcc_db_total_size_in_bytes Total size of the underlying database physically allocated in bytes.
# TYPE etcd_mvcc_db_total_size_in_bytes gauge
etcd 分配的db大小(使用量大小+空闲大小)
# HELP etcd_mvcc_db_total_size_in_use_in_bytes Total size of the underlying database logically in use in bytes.
# TYPE etcd_mvcc_db_total_size_in_use_in_bytes gauge
etcd db的使用量大小
# HELP etcd_mvcc_range_total Total number of ranges seen by this member.
# TYPE etcd_mvcc_range_total counter
etcd执行range的数量
# HELP etcd_mvcc_put_total Total number of puts seen by this member.
# TYPE etcd_mvcc_put_total counter
etcd执行put的数量
# HELP etcd_mvcc_txn_total Total number of txns seen by this member.
# TYPE etcd_mvcc_txn_total counter
etcd实例执行事务的数量
# HELP etcd_mvcc_delete_total Total number of deletes seen by this member.
# TYPE etcd_mvcc_delete_total counter
etcd实例执行delete操作的数量
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
etcd cpu使用量
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
etcd 内存使用量
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
etcd 打开的fd数目