ESLint 机制分析与简单插件实践
前言
代码是写给人看的,所以一份好的代码,是要让水平不一的阅读者,都能够理解代码的本意。每个人的代码风格是不可能完全相同的,例如在一个文件里,有的以两个空格做缩进,有的以四个空格做缩进,有的使用下划线,有的使用驼峰,那么它的阅读体验就会变得很差。
所以如何来对代码进行约束,使团队的代码风格尽量统一,不产生更多的理解成本,是一个需要解决的问题。众所周知,懒是社会生产力进步的源动力,所以...
在前端工程化的标准中有一项就是自动化,自动化当中就包括了代码规范自动化。实现代码规范自动化可以解放团队生产力,提升团队生产效率,balabla... 所以 ESlint、TSLint、StyleLint这些工程化插件应运而生。
而最近在笔者团队也在统一不同的项目之间的规范差异,相信大家也都遇到了大段飘红的现象,今天咱来简单探究一下背后涉及到的原理。
What is ESLint/Lint?
首先,提到ESlint,应该会想到两种东西,一个是ESLint的npm包,也就是我们 devDep里面的, 另一个是我们所安装的比如VSCode的ESLint插件,那么这两个东西有什么联系呢。

Npm包:是实际的lint规则以及我们执行lint的时候,控制代码如何去进行格式化的。
Vscode插件: 实际指向我们项目的 /node_modules/eslint 或者全局的eslint,通过eslint的规则,告诉IDE,哪些地方需要飘红。也就是说插件是在解析我们的打开的文件,同时和规则对比,是否存在eslint问题。以及可以通过我们的IDE配置,在不同的时机去执行我们的lint,比如保存自动格式化。
总而言之, eslint 规则就是对我们的代码风格和代码中潜在的一些错误和不规范用法的一个约束,通过npm包的形式引入项目,同时通过IDE的插件,读取npm包规则,对我们的代码进行错误提示,
How to Use it?
如何在项目配置ESlint就不在本文赘述了。大多数脚手架其实都会给你初始化好基本的ESlint。涉及到的工具不同可能会有些许的不一样,不过都大差不差。这段讲一下ESLint中的主要配置项。如果有兴趣深一步研究,可以移步eslint的官网文档 [1],对默认的规则集[2]感兴趣 也可以移步 。
打开一个eslintrc文件,一般来说,有几个选项。这里以json为例,来简单说明下每个字段。
https://mp.weixin.qq.com/s/wYYDG7yU9h3-6DBYTCkuiAeslint支持以下几种格式的配置文件,如果同一个目录下有多个配置文件,ESLint 只会使用一个。优先级顺序如下:
.eslintrc.js.eslintrc.yaml.eslintrc.yml.eslintrc.json.eslintrcpackage.json
同时 eslint 也支持对每个目录配置不一样的规则,对于mono仓库下,可能每个repo的eslint都有些许的区别,这个时候我们就可以采用下面的目录格式,根目录下存在基本规则,子app下存在特定的规则。子rc是对父rc的一个override,但是如果我们在app/.eslintrc.js中设置了root:true,那么对于test.js,父目录中rc使用的规则,在app中不会生效。
packages
├── package.json
├──.eslintrc.js
├── lib
│ └── test.js
└─┬ app
├── .eslintrc.js
└── test.jsWhy does it work?
AST
他是为什么能够生效的。这里就要提到我们前端方方面面都要涉及到的AST了,感谢新时代。
ESLint是基于抽象语法树来进行工作的,ESLint默认使用的编译器(parse)是 Espree[3],通过它来解析我们的JS代码生成AST,基于AST,我们就可以对我们的代码进行检查和修改了。
通常我们的Babel编译分为下图这几步,编译/转换/生成。ESlint和它对比,只有第一步是一致的, 因为我们只需要拿到ast中的部分信息,同时直接在源码中进行提示和操作就行,并不需要transform和后续的生成代码。

解析
现在我们通过demo来探究他背后的原理以及转换的方式。首先,我们需要加载和解析我们的源代码。这就是编译器将我们的代码转换成AST树的一个过程。因为已经全面拥抱typescript(主要是因为espree没有类型注解,我难受),所以本文使用 @typescript-eslint/parser来作为我们的编译器。这里有个小坑,如果在VSCode安装了import cost插件的话,他去解析这个parser会特别卡,所以可以暂时禁用。
const foo = "anthony"
const bar = "dst"import fs from 'fs';
import path from 'path';
import * as tsParser from '@typescript-eslint/parser';
const filePath = path.resolve('./src/test.ts')
const text = fs.readFileSync(filePath, "utf8")
// 编译成 AST 这里是不是和eslint的配置项对上了,没错就是透传而已
const ast = tsParser.parse(text,{
comment: true, // 创建包含所有注释的顶级注释数组
ecmaVersion: 6, // JS 版本
// // 指定其他语言功能,
// ecmaFeatures: {
// jsx: true, // 启用JSX解析
// globalReturn: true // 在全局范围内启用return(当sourceType为“commonjs”时自动设置为true)
// },
loc: true, // 将行/列位置信息附加到每个节点
range: true, // 将范围信息附加到每个节点
tokens: true // 创建包含所有标记的顶级标记数组
})然后我们将获得的ast打印一下,简单从下图可以看到主要包含的内容。本地打印出来可能不太方便阅读,也可以使用在线的工具[4],将解析器设置为@typescript-eslint/parser。相对于espree来说,ts解析多出来的部分中,比较关键的就是右图这段,决定我们如何去解析他的类型。
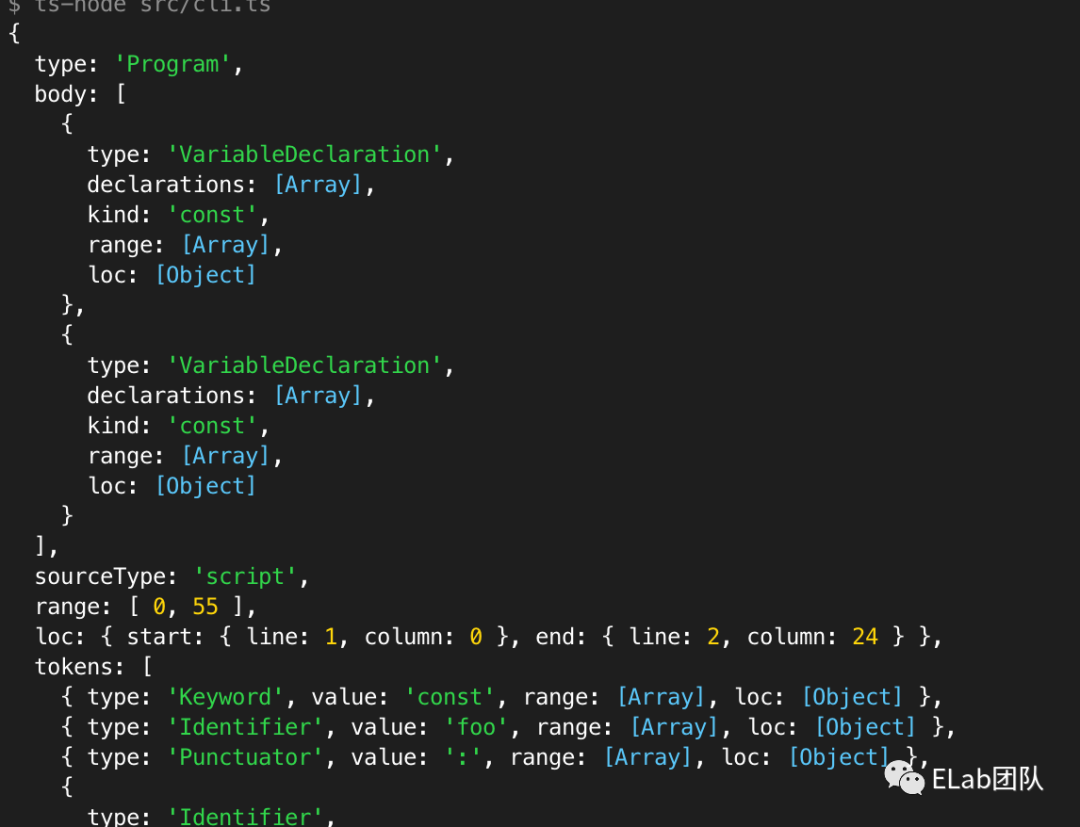

AST 就是记录了读取源文件之后的文本内容的各个单位的位置信息,这样我们就可以通过操作 AST 修改需要修改的内容,然后再根据修改后的 AST 信息进行修改对应的文本内容。比如我们把上文中的 const 关键字修改成 let ,那么我们就先对 AST 对应的const内容进行修改为 let ,得到修改之后的 AST 数据,再根据修改后的 AST 数据去修改对应的文本内容。所谓的修改就是字符串替换,因为我们已经知道了对应的位置信息。
SourceCode
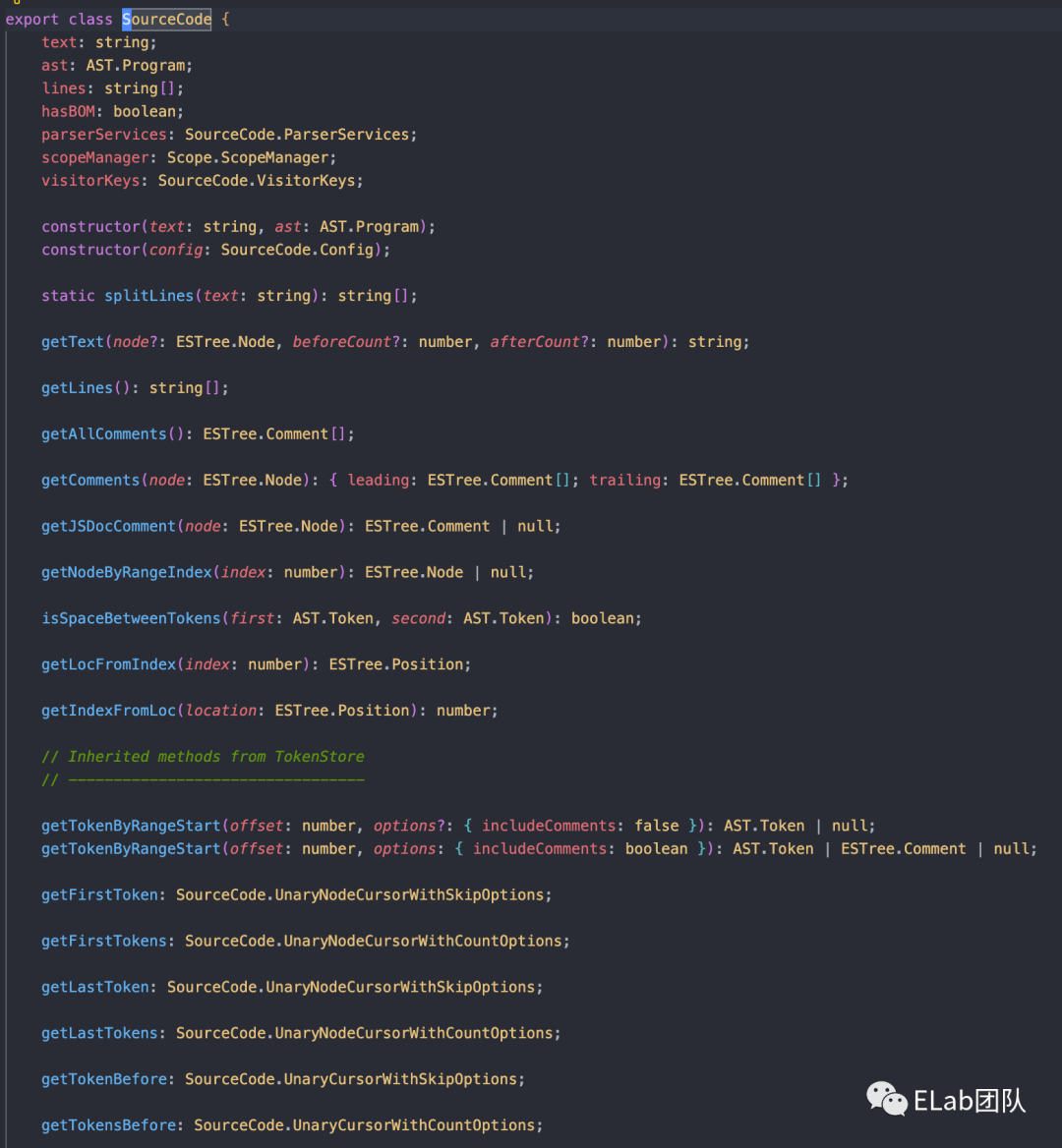
但是根据上面我们可以看到,直接根据ast去查找然后比对替换,效率是很低的,而且嵌套比较深。这个时候ESlint是怎么干的呢?他生成了一个新的结构用于我们操作,也就是SourceCode。有兴趣进一步探究可以自行查阅源码的 sourcecode/source_code.js部分。简单来说,就是构建了一个SourceCode实例,接受两个参数,原文text 和解析后的ast,然后返回我们一个包含茫茫多方法的实例对象。
import { SourceCode } from 'eslint';
// ....
//
const sourceCode = new SourceCode(text,ast);
// 这打个断点,看看sourceCode结构 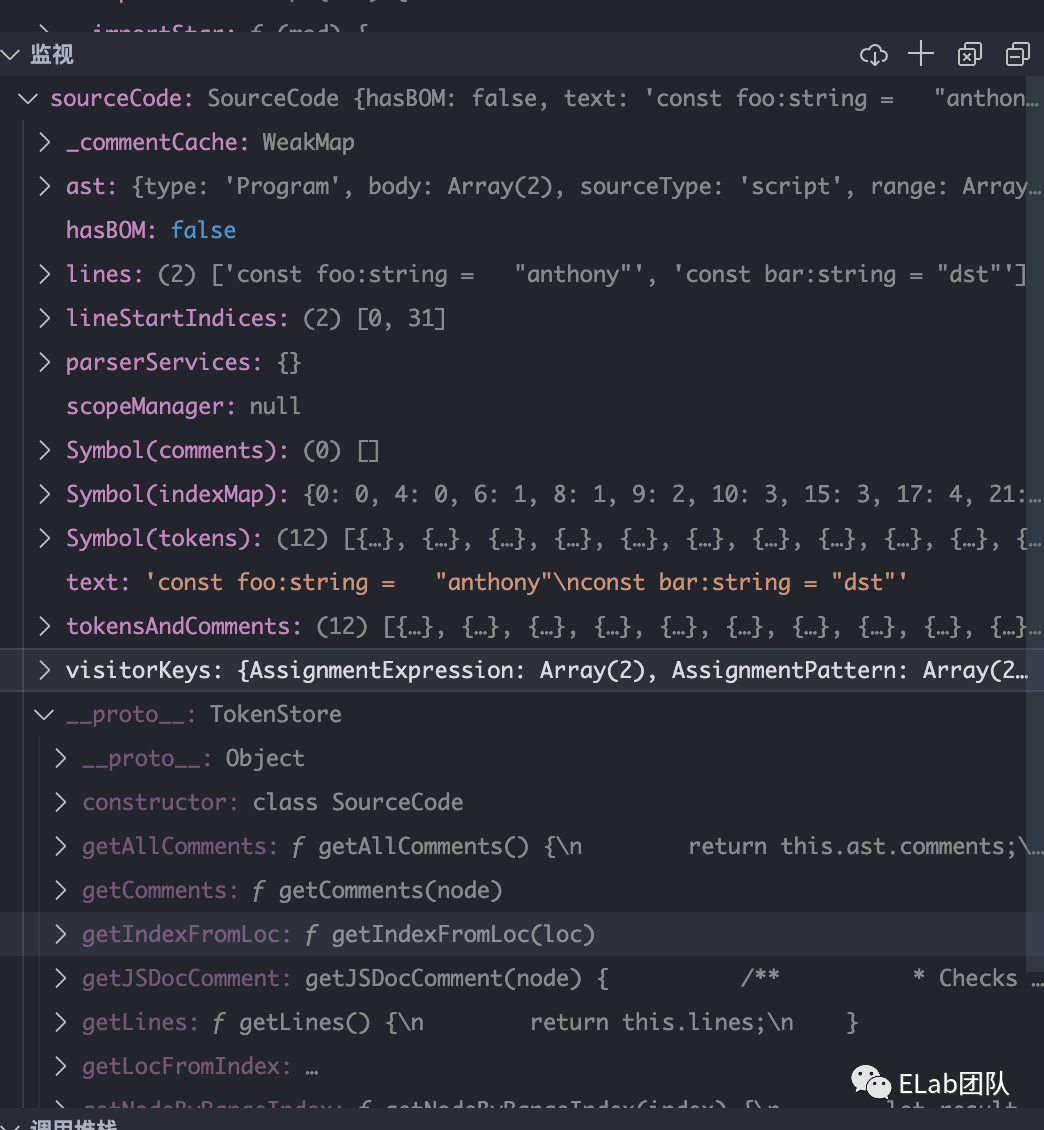
- 简单来讲解(摘抄)一下实例对象里面的一些属性和
__proto__上的方法,完整属性可以查阅官网[5]/源码/类型注解。
- hasBOM:是否含有 unicode bom[6]
- lines:将我们的每一行切割,分行形成的一个array
- linsStartIndices: 每行的开始位置
- tokenAndComments: token和comment的一个有序集合。
getText(node?: ESTree.Node, beforeCount?: number, afterCount?: number): string;isSpaceBetweenTokens(first: AST.Token, second: AST.Token): boolean;两个token间是否有空格。- visitorKeys: 存在的key值。
好了 前置的一些知识我们已经介绍的差不多了。接下来 结合实际的rules demo来进行讲解。
规则模版
相信如果有写过vscode插件的同学应该对 Yeoman 不陌生,eslint也有提供基于Yeoman的一套脚手架用于生成模版。
首先全局安装eslint 的脚手架,npm install -g yo generator-eslint,然后通过下面的一些交互式命令行操作来初始化我们的操作。
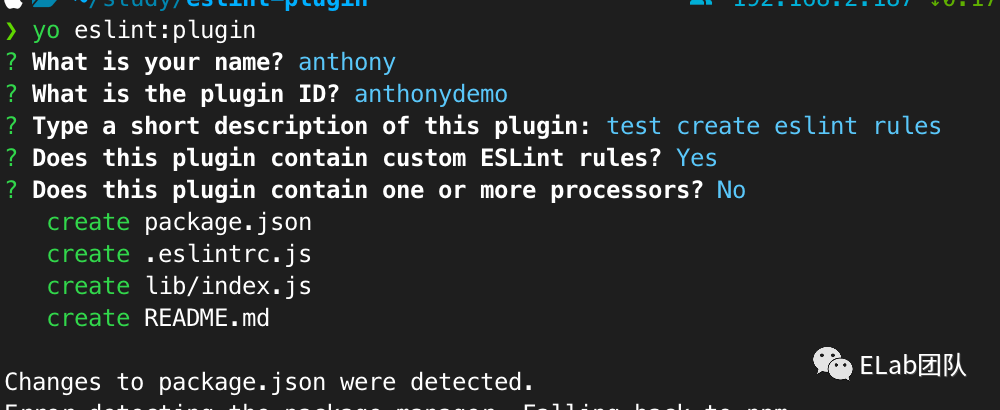
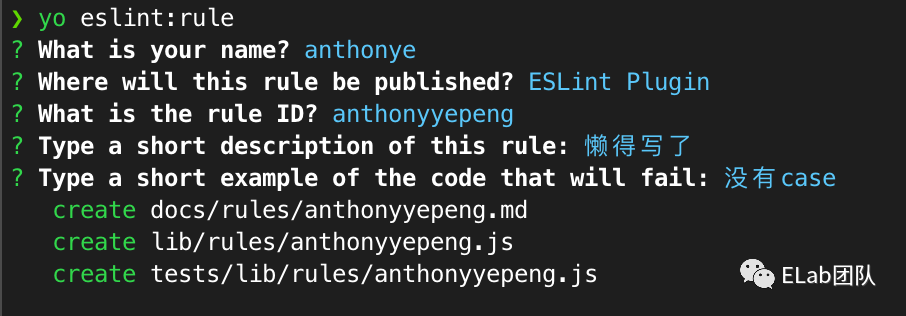
通过初始化,我们可以看到一个以下的文件的壳子,我们在里面添加一些我们上面所讲到的东西。打开我们生成的规则模版文件,同时在里面添加一些规则和提示(注意,这里我的写法不规范,我将两种无关规则放在了一个规则文件里)。
"use strict";
/** @type {import('eslint').Rule.RuleModule} */
module.exports = {
meta: {
type: 'problem', // `problem`, `suggestion`, or `layout`
docs: {
description: "xxxx",
recommended: false,
url: null, // URL to the documentation page for this rule
},
messages:{
temp:'不样你用字面量作为函数的参数传入',
novar: '不样你用var声明',
noExport: '退出时执行这个'
},
fixable: 'code', // Or `code` or `whitespace`
schema: [], // Add a schema if the rule has options
},
create(context) {
// variables should be defined here
const sourceCode = context.getSourceCode();
return {
ArrowFunctionExpression:(node)=>{
if(node.callee.name !== 'abcd') return;
if(!node.arguments) return;
node.arguments.forEach((argNode,index)=>{
argNode.type === "Literal" && context.report({
node,
messageId: 'temp',
fix(fixer){
const val = argNode.value;
const statementString = `const val${index} = ${val}\n`;
return [
fixer.replaceTextRange(node.arguments[index].range, `val${index}`),
fixer.insertTextBeforeRange(node.range, statementString)
]
}
})
})
},
"Program:exit"(node) {
context.report({
node,
messageId: "noExport",
});
},
VariableDeclaration(node){
if(node.kind === 'var') {
context.report({
node,
messageId: 'novar',
fix(fixer) {
const varToken = sourceCode.getFirstToken(node)
return fixer.replaceText(varToken, 'let')
}
})
}
}
};
},
};关键函数
在这个demo里面,我们看到几个东西,一个是create函数的参数 context 以及他的返回值,还有就是context上提供的report方法 以及report接受的fix参数。这几个加起来,形成了我们一条规则的校验逻辑,通过遍历,我们到了某个ast节点,如果某个ast节点满足了我们所写的某条规则,我们进行report,同时提供一个修复函数,修复函数通过token或者range来决定对某处进行文本替换。
接下来,挨个来讲解这些东西,首先是context的上下文形成,这个没有什么好说的,其实就是创建了一个对象,然后提供了一些一些方法,供我们在插件中访问上下文使用,然后对于每个rule都在createRuleListener中都创建了一个listener,这里我们在后面串整体流程时还会再过一遍。
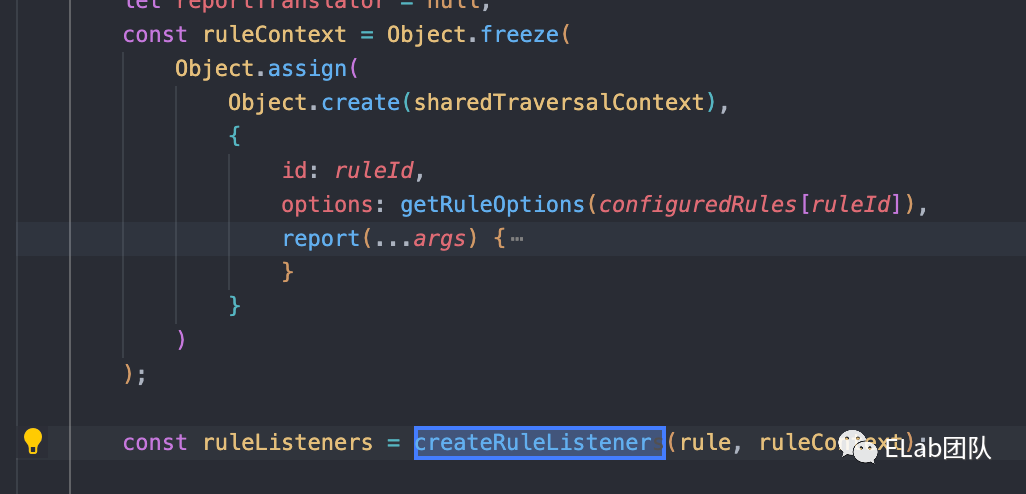
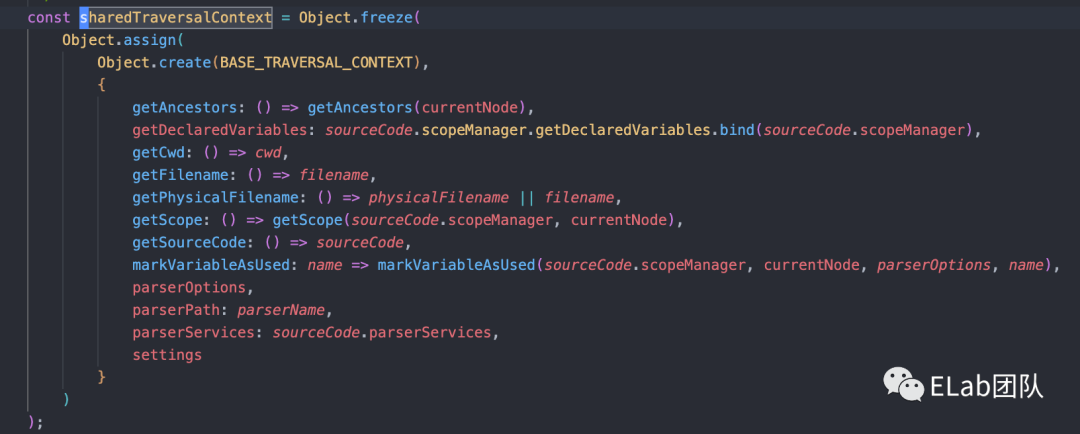
接着是report 方法,简单分析下这块代码,其实就是通过一系列的操作,然后往lintingProblem这个数组里面推了一个problem。这个problem包含一些错误信息,ast信息等等。
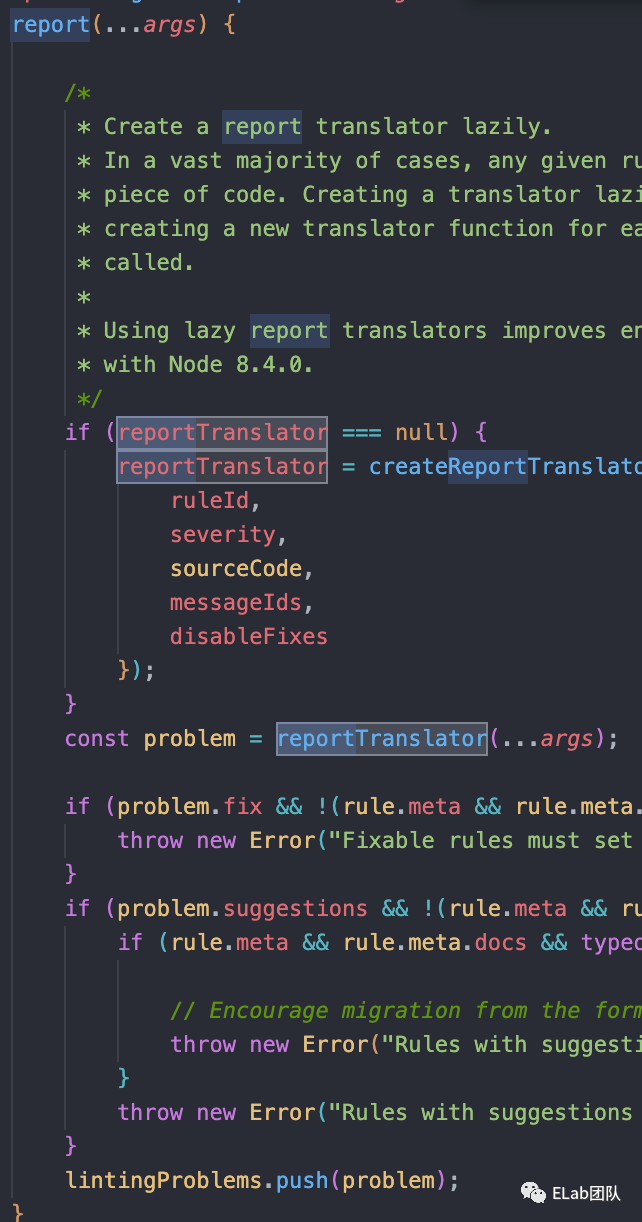
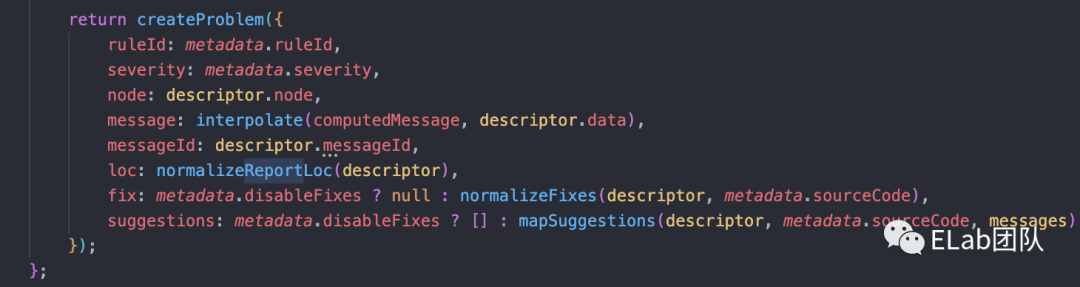
最后是我们的fix,我们上面用到的所有replace方法,其实都殊途同归,最后回到了这里,大道至简,简单的slice和+=完成了我们的修复动作。
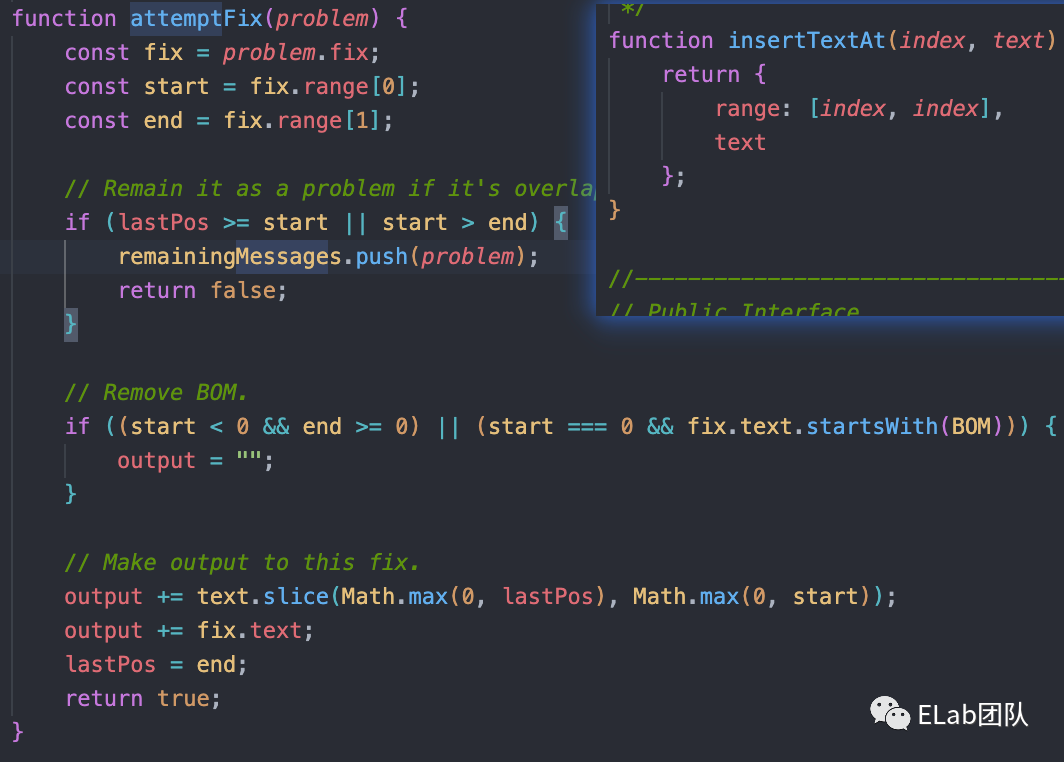
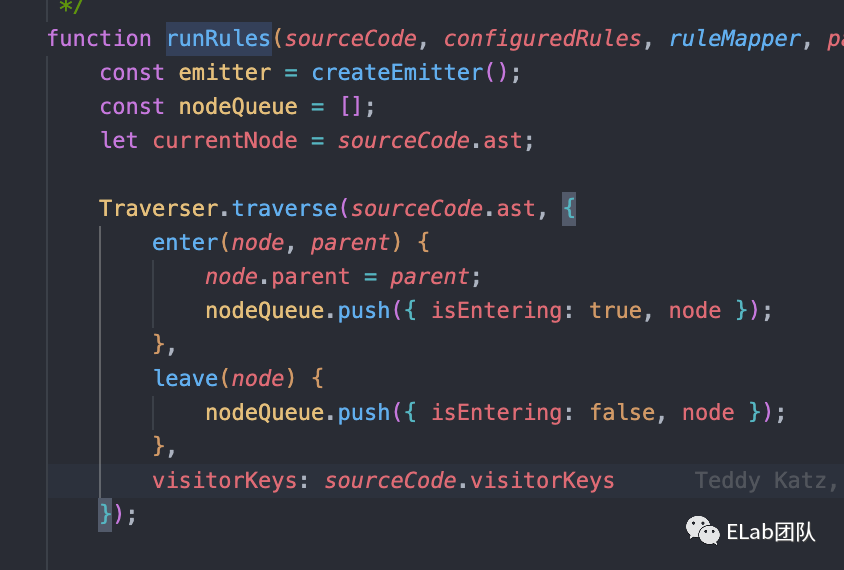
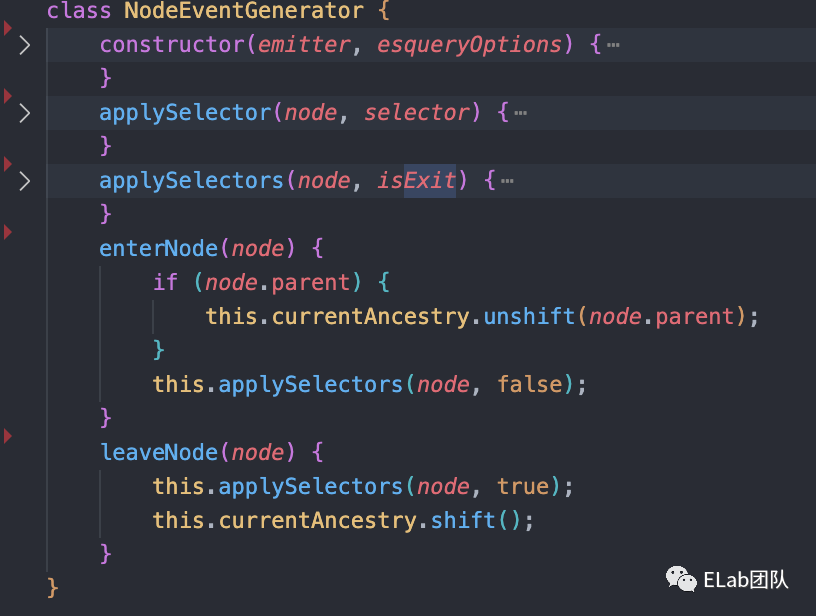
linter.js中的runRules方法。
整体流程
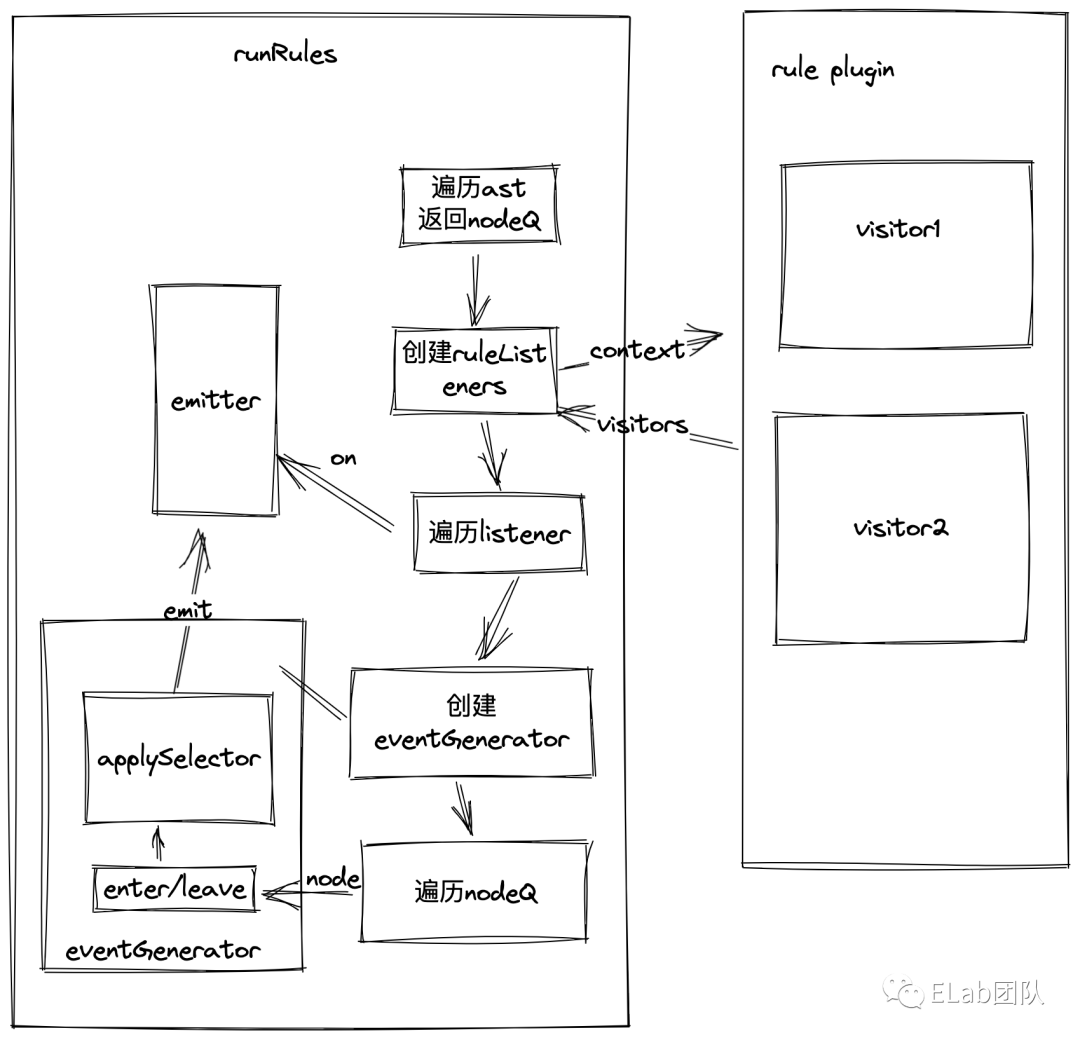
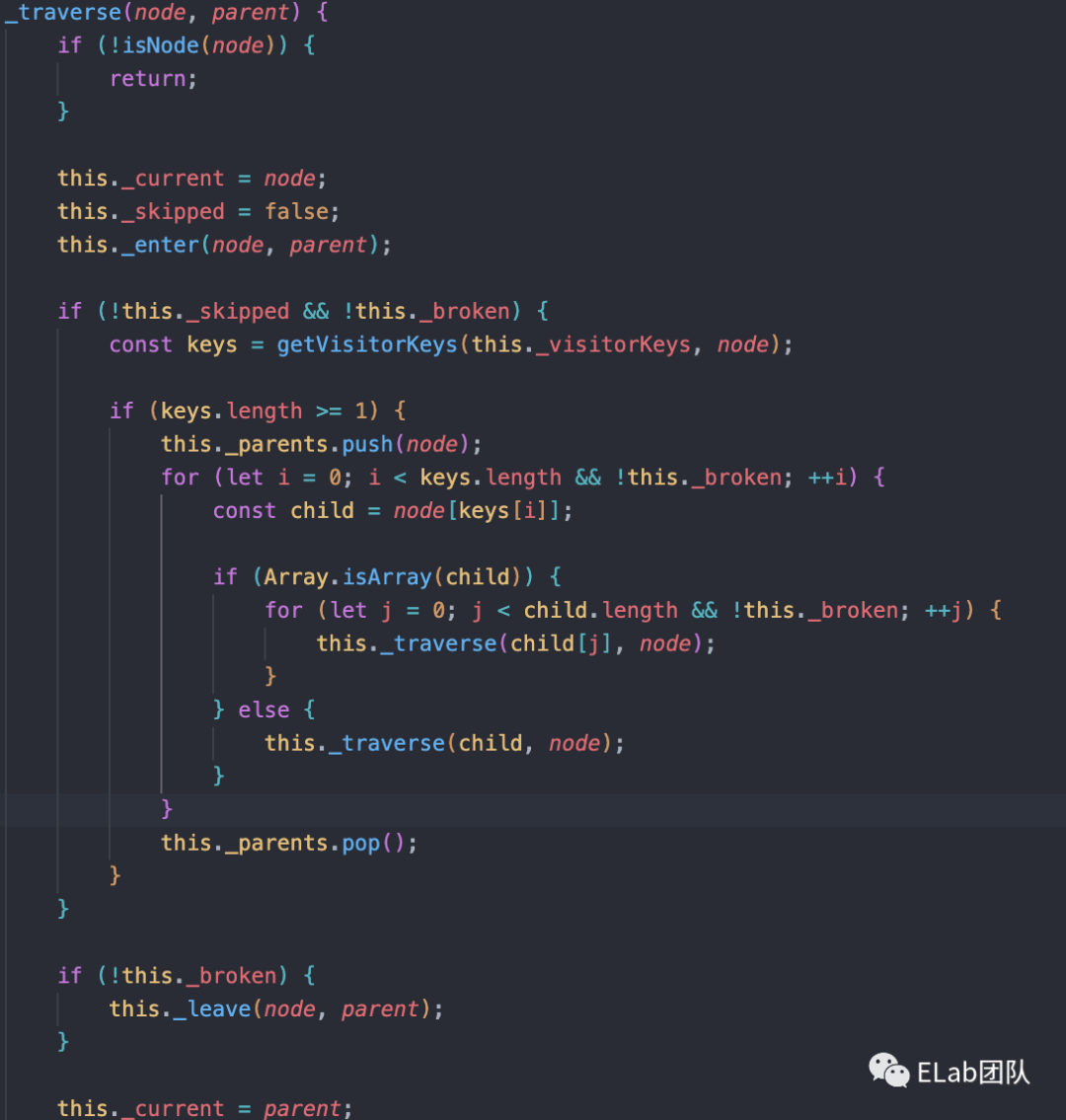
Traverser.traverse,传入了ast和一个对象,包含enter、leave和visitorKeys。这个函数的作用就是进行一个递归遍历,同时在遍历的时候通过enter和leave我们在队列中存储了两个相同的节点,一个是进入时,一个是退出时,方便我们后续处理。这里涉及到一个设计模式,访问者模式(用于数据和操作解耦),通过在遍历时加上isEntering,可以让我们决定是在进入时还是退出时执行访问者逻辑。
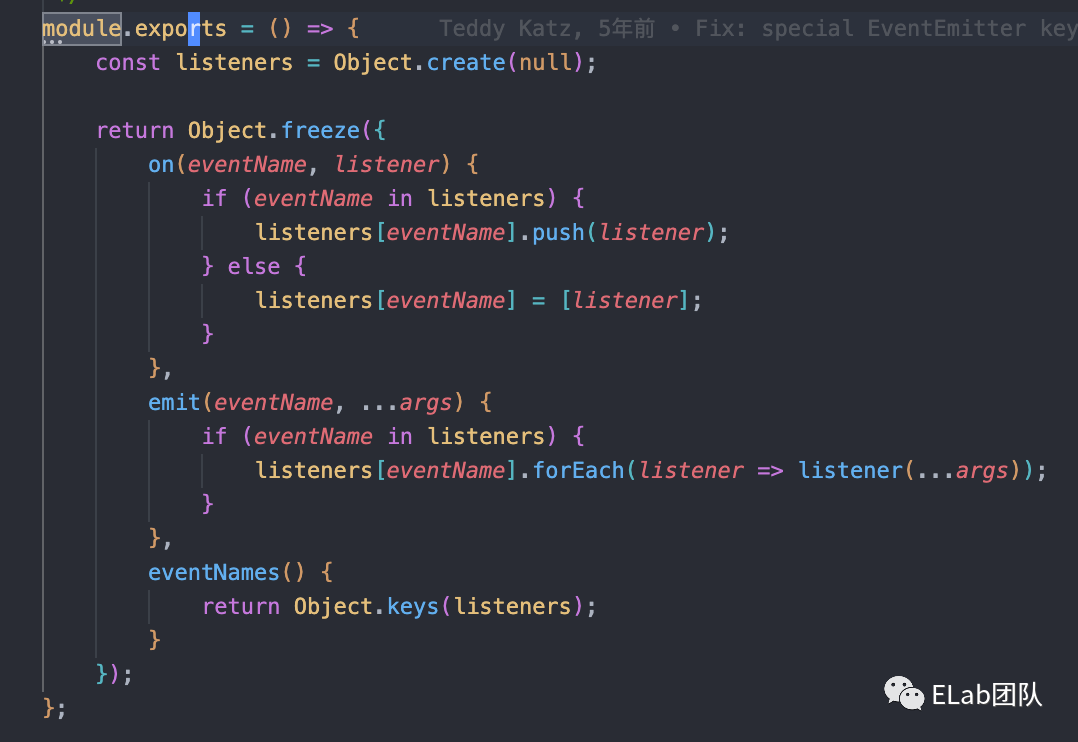
接着我们需要把我们的所有规则都给像上面讲的给创建成ruleListener,然后在我们的nodeQueue后续遍历时,触发某些逻辑。当然,这里大家可能都想到了订阅发布模式,这个也是在我们整个逻辑中比较重要的一环,遍历时,通过emit推送消息,然后让ruleListener决定是否需要执行某些逻辑,所以,我们需要对Listener订阅上某些事件。

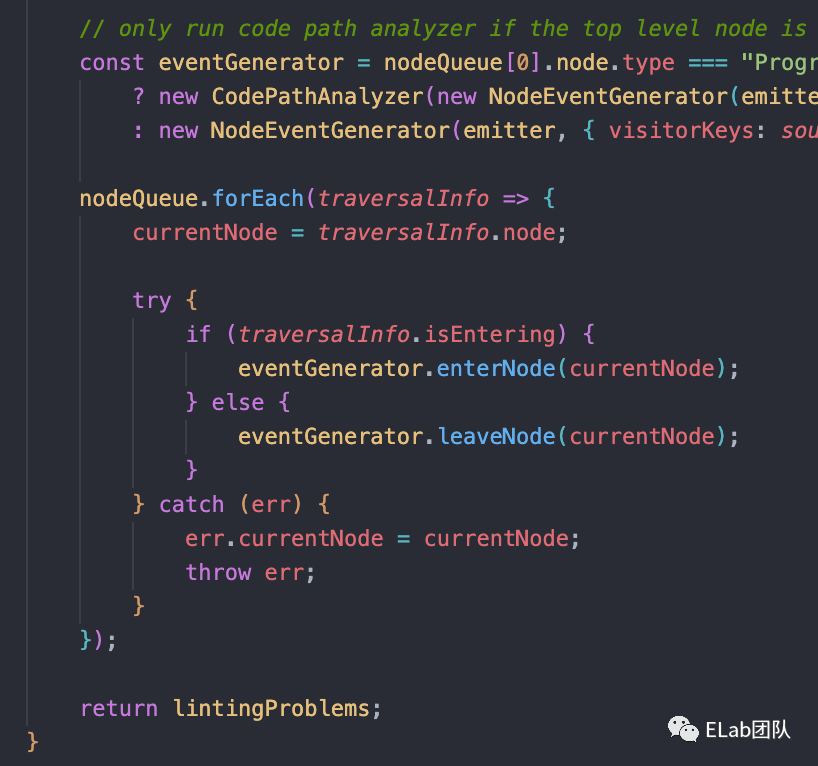
接下来,就是对我们的nodeQueue遍历了,通过我们节点上打上的标,来决定是在执行进入逻辑还是离开逻辑。这里我就不展开讲具体的细节了,其实简单理解就是通过enter和leave的时候去触发不同的visitor的动作。
后语
限制于时间因素,本文成文比较仓促,可能会有一些知识点的缺失或者不对,敬请大家斧正。同时本文仅是初步的探索了其背后的原理,根据原理,后续可以做的一些例如eslint插件等等并没有详细的阐述。大家下来可以自行探索。
最后送大家一句话,linus 说的,也是我比较信奉的一句话。talk is cheap, show me the code,想了解一个东西,最好的办法就是简单实现它。我相信大家在解析完它的流程后,都能够简单实现一个eslint的小demo,以及能够上手写一写eslint-plugin。
参考资料
[1]官网文档 : https://eslint.org/docs/latest/user-guide/configuring/configuration-files
[2]默认的规则集: https://eslint.org/docs/latest/rules/
[3]Espree: https://github.com/eslint/espree
[4]在线的工具: https://astexplorer.net/
[5]官网: https://eslint.org/docs/latest/developer-guide/working-with-rules
[6]unicode bom: https://en.wikipedia.org/wiki/Byte_order_mark
- END -