【译】Linux Conntrack:为什么它会崩溃,如何避免这个问题
一个互联网技术玩家,一个爱聊技术的家伙。在工作和学习中不断思考,把这些思考总结出来,并分享,和大家一起交流进步。
Conntrack 这个话题也是非常复杂且重要的,文章中的案例在我们实际场景中确实遇到过,这篇文章总结的挺到位,但是没有进一步从原理解释如何实现 doNotTrack 及其原理。
原文地址:https://www.tigera.io/blog/when-linux-conntrack-is-no-longer-your-friend/
前言
连接跟踪(“conntrack”)是 Linux 内核网络栈的核心特性。它允许内核跟踪所有的逻辑网络连接或数据包流,从而识别组成每个流的所有数据包,以便能够统一的处理它们。
Conntrack 是一个重要的内核特性,它支撑了一些关键的很重要的应用场景:
- NAT 根据连接跟踪信息,可以以相同的方式转换这个流中的所有数据包。例如,当一个 pod 访问 Kubernetes 服务时,kube-proxy 的负载平衡使用 NAT 将连接重定向到一个特定的后端 pod。这个连接就是记录到 conntrack 表中,到服务 IP 的数据包应该都发送到相同的后端 pod,从后端 pod 返回的数据包应该做反向 NAT 才能返回到源 pod。
- 有状态防火墙,例如 Calico,根据连接跟踪信息来精确地将“响应”流量列入白名单。你可以编写一个网络策略,如“允许我的 pod 连接到任何远程 IP”,而不是编写策略显式地允许响应流量。(如果没有这一点,你就需要添加更不安全的规则如“允许数据包从任何 IP 进入我的 pod”。)
此外,conntrack 通常可以提高性能(减少 CPU 和数据包延迟),因为只有数据流中的第一个数据包需要经过完整的网络堆栈处理,通过第一个包的处理确定后续包怎么处理。请参阅“compare kube-proxy-modes”博客,可以进一步深入理解。
但是,conntrack 也是有局限性的。。。
那它会在哪里出问题呢?
conntrack 表有一个可配置的最大值,如果 conntrack 表被添加到了最大值,连接通常会开始被拒绝或丢弃。对于大多数工作负载来说,conntrack 表的大小是没问题的,也永远都不是问题。然而,在一些情况下,conntrack 表需要多注:
- 最明显的情况是如果你的服务同时处理大量的活动连接。例如,如果你的 conntrack 表配置为128k 的大小,但您有>128k 的并发连接,那么肯定会遇到问题!
- 另外一种不太明显的情况是,如果服务每秒钟处理非常高的连接数。即使是短连接,Linux 也会持续跟踪一段时间的(默认为120秒)连接。例如,如果 conntrack 表被配置为128k 大小,并且想每秒处理 1100 个连接,那么即使是短连接,这也将超过conntrack表的大小(128k / 120s = 1092个连接/秒)。
有一些小众的工作负载类型就属于这些类别。此外,如果处于一个敌对的环境中,用大量半开的连冲击没你的服务就可以被用作拒绝服务攻击。在这两种情况下,conntrack 都可能成为系统中的瓶颈。对于某些场景,通过增加 conntrack 表大小或减少 conntrack 超时时间来调优 conntrack 可能足以满足你的需求(但如果调优错误,可能会带来很多麻烦)。对于其他场景,你要让违规流量绕过 conntrack。
一个真实的例子
举一个具体的例子,我们合作过的一个大型 SaaS 提供商有一组 memcached 服务运行在裸服务器上(未虚拟化或容器化),每台服务器每秒处理 50k+ 短连接。实际上这远远超出了标准 Linux 配置所能处理的范围。
他们已经尝试通过调优 conntrack 配置来增加表的大小和减少超时时间,但是这种场景下这样的调优并不是最佳办法,最大的问题就是增加了内存的使用(大概是 GBytes!),而且是短连接的情况下, conntrack 没有提供通常的性能优势(减少 CPU 使用或是包延迟)。
相反,他们使用了 Calico。Calico 的网络策略允许特定的流量绕开conntrack(使用 doNotTrack 标志)。这为他们提供了所需的性能,以及 Calico 带来的额外安全好处。
绕开 conntrack 有什么好处?
- 不跟踪网络策略通常必须是对称的。在 saas 提供者的那个案例中,他们的工作负载是内部的,因此使用网络策略,他们可以小范围地将所有允许访问 memcached 服务的工作负载的流量列入白名单。
- 不跟踪策略不关注连接的方向。因此,如果一个 memcached 服务被破坏,理论上只要它使用了正确的源端口,它就可以尝试连接到任何一个 memcached 客户端。但是,假设你为 memcached 客户端定义了正确的网络策略,那么这些连接尝试仍然会在客户端被拒绝。
- 不跟踪网络策略应用于每个包,而正常网络策略只应用于流中的第一个包。这可能会增加每个包的 CPU 成本,因为每个包都需要由网络策略处理。但是对于短连接,这种额外的处理开销被不使用 conntrack 的优化所抵消。例如,在SaaS提供商的案例中,每个连接中的数据包数量非常少,因此对每个数据包应用策略的额外开销是合理的。
真实测试
我们测试了单个 memcached 服务 pod 和许多运行在远程节点上的客户端 pod,因此我们可以每秒发动非常多的连接。memcached 服务 pod 主机是 8 核的和一个 512k 配置的 conntrack 表(主机大小的标准设置)。我们测量了以下几种情况下的性能差异:无网络策略;Calico 正常网络策略和 Calico 不跟踪网络策略。
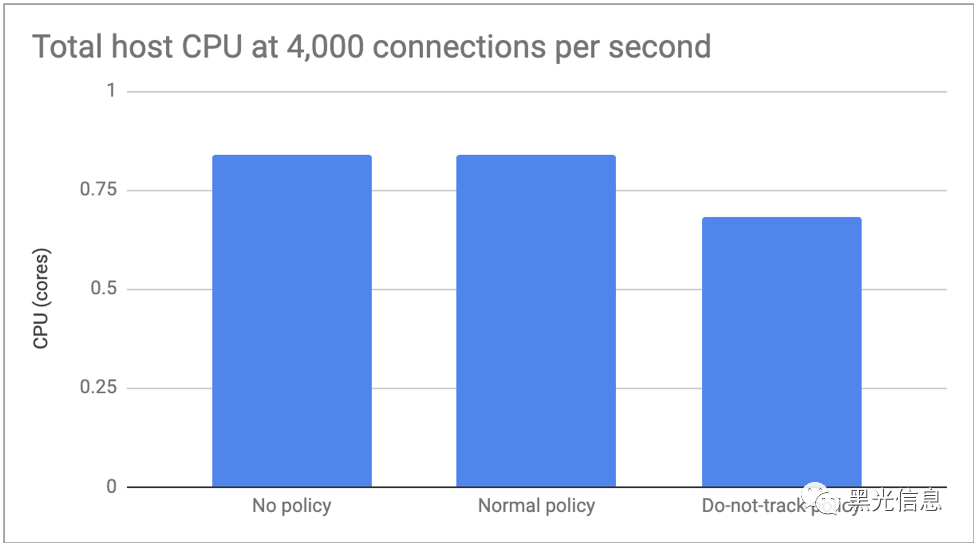
在第一个测试中,我们将每秒的连接限制在 4000 个,这样我们就可以关注 CPU 的差异。无策略和正常策略在性能上没有可测量的差异,但不跟踪策略的 CPU 负载减少了大约 20%。
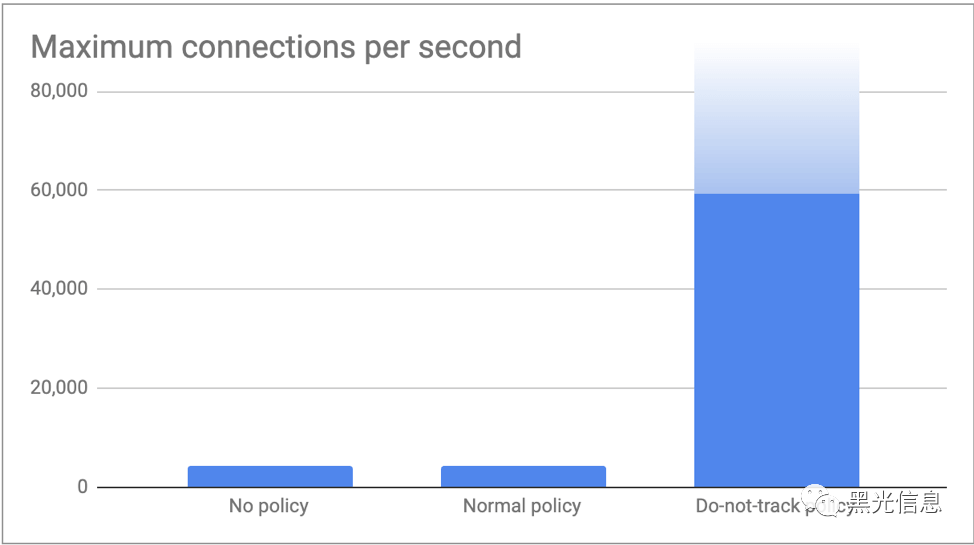
在第二个测试中,我们推送了尽可能多的客户端连接,并测量了 memcached 服务器每秒能够处理的最大连接数。正如预期的那样,没有策略和正常策略都达到了 conntrack 表限制,即略高于每秒 4,000 个连接(512k / 120s = 4,369个连接/秒)。在不跟踪政策实施的情况下,我们的客户每秒推送了 60,000 个连接,而没有遇到任何问题。我们很有信心,我们可以通过增加更多的客户来超越这一点,但感觉数字已经足够说明这篇博客的要点!
结论
Conntrack 是一个重要的内核特性。它很擅长自己的工作场景。许多主要的使用场景都依赖于它。然而,对于一些小众场景,conntrack 的开销超过了它所带来的正常好处。在这些场景中,可以使用 Calico 网络策略选择性地绕过 conntrack,同时仍可以加强网络安全性。对于所有其他流量,conntrack 仍然是你的好朋友!