【总结】1519- 从一个 bug 中延伸出 canvas 最大内存限制和浏览器渲染原理

前几天一个同事让我帮忙解决一个 bug,这个 bug 困扰他好几天了。这是一个 App 中的 Hybrid 页面,它瀑布流中的图片总是划着划着有几张图片是白图(加载不出来),越往下划出现的概率越大,而且这个问题只有 iOS 上才出现,Android 是正常的。
首先我问他会不会是图片兼容性的问题,比如低版本的 Safari 是不支持 webp 格式的图片的。他说这个页面中的图片并不是 http-url 类型的图片,都是由 canvas 渲染出来的 base64 dataURL。那这就排除了图片格式兼容性的问题。
于是我向他更进一步了解业务场景是什么,为什么会用到 canvas。下面先给大家讲讲这个业务的使用场景:
首先我随便搜索一张图,比如『杨幂』
最终决定的方案是由前端渲染,一来可以尝试更多挑战;二来如果由客户端渲染,将来前端页面难以脱离成纯 web 页,控制权交给别人会让自己无法面对更多变数;三来如果交给后端,会产生更多网络 io 的延迟,降低用户体验。这种滤镜、多图片叠加的场景自然是用 canvas 比较合适,而且由于之前我们就在使用一个 canvas 库:Konva,所以这次还是使用了它。后来就出现文章开头提到的问题。
幸好我们在开发环境下的移动端页面接入了 devtool 工具,所以在手机上也是能看到报错信息的。报错如下:
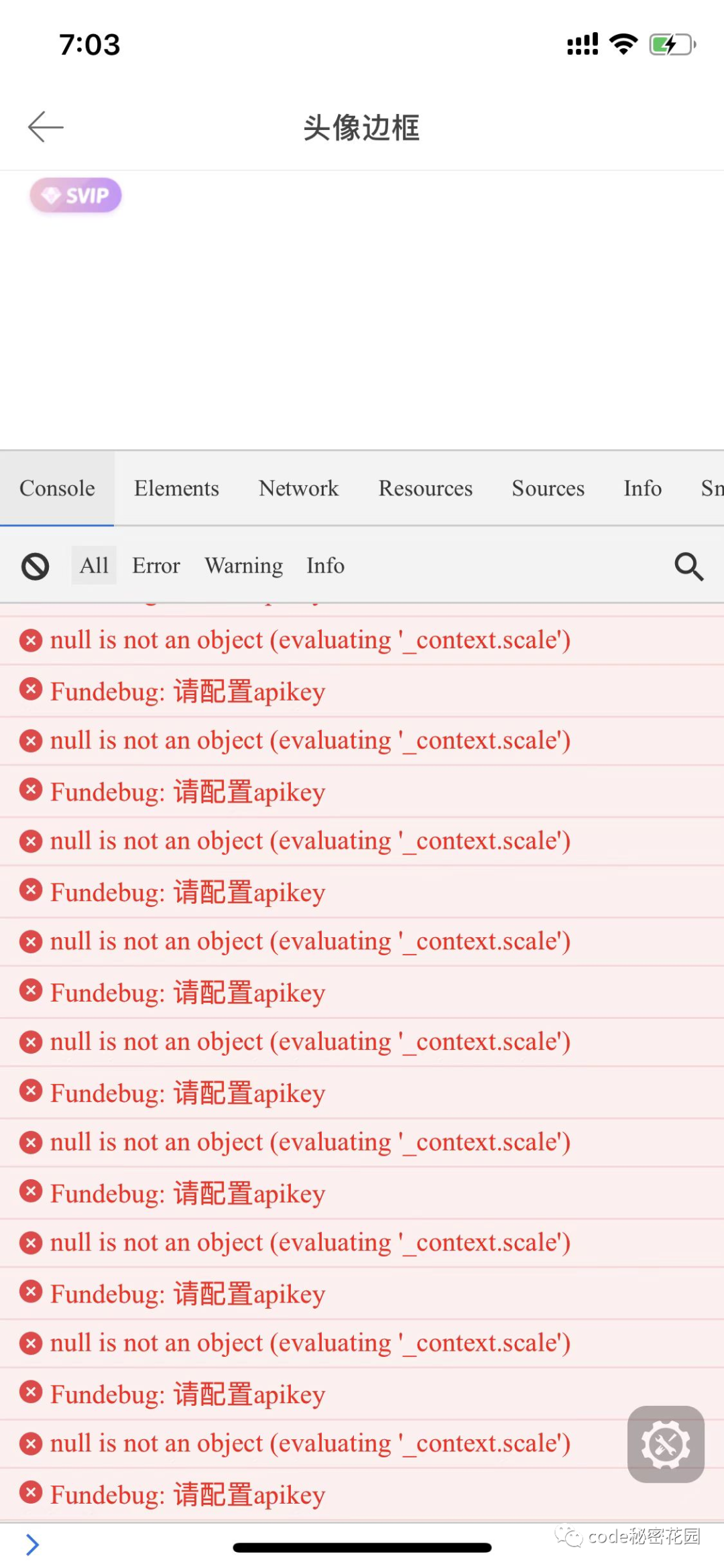
.scale这个方法,那么会不会是引入的某个库做的呢,也因此没有 map 文件难以发现真正的代码位置。只能去项目 dist 搜索。经过分析项目 dist 代码,发现只有这么一处。
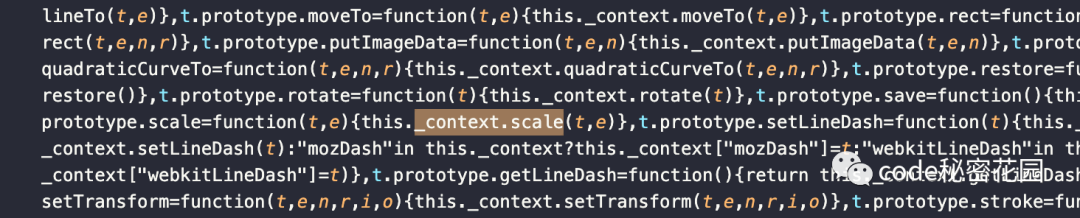
_context是什么。
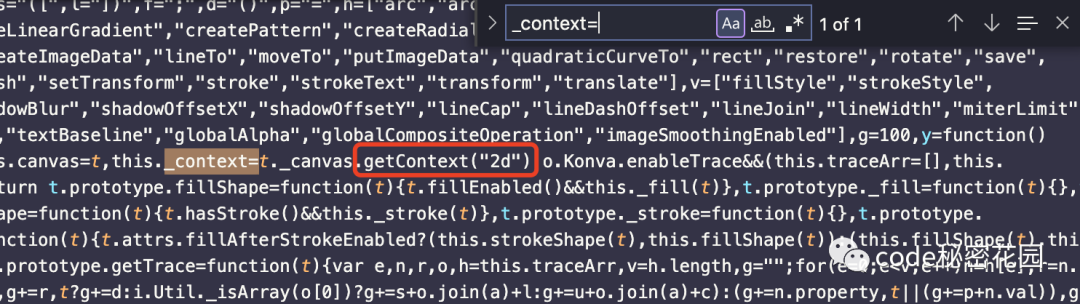
canvas.getContext('2d')返回的 context。那么为什么getContext('2d')会返回null呢。
有一种可能是,先执行了getContext('3d'),又执行了getContext('2d'),显然这里不可能。
另一种可能是,不同的浏览器内核对 canvas 的处理策略不一样,它可能超出了 Safari 浏览器的限制,而 chrome 是没有这个限制,所以安卓手机是正常的。这一点是我在 stack overflow 看到有人这么说才确定的,这里贴个原文 (https://stackoverflow.com/questions/40482586/getcontext2d-returns-null-in-safari-10)。
I'm not sure if this is relevant to the situation described here, but I had a similar situation which I was able to solve. Perhaps this helps somebody down the line. The gist of the problem was that browsers deal with HTML5 canvases quite differently. In particular, the amount of memory they are willing to allocate to canvases en total and to individual canvases (constraints on height, width, and area) seem to differ. I never bothered to grok the details, but here's a stack question addressing some of the constraints
For me, I was generating many independent canvases and managing their 2d context separately. The problem is that I wasn't being careful with garbage collection, and it took me a long time to notice it because I was testing for the most part in Chrome, in which everything worked fine.
Meanwhile the behavior in firefox was that my project became totally unresponsive without throwing meaningingful errors, and in Safari i could get my contexts fine until i ran out of total memory to allocate to canvases, and then getContext('2d') would return null.
My first solution was to reduce the resolution of my canvases, but the better solution was to dispose of the ones I wasn't currently using and generate them on the fly.
大意是 chrome、Firefox、Safari 等浏览器对 canvas 的总内存占用限制、单个 canvas 的限制(如 width、height、像素密度)不尽相同。在大量使用 canvas 时没有注意即使回收,导致了他在 chrome 测试没问题的代码,Firefox 中完全没有反应,在 Safari 中报错。
有了相似情况的借鉴,大概知道了问题所在,回到我的项目中看看能如何优化。为了尽快展示图片,瀑布流中每个图片虽然都需要一个 canvas 渲染,但图片实际使用的是 canvas 生成的 base64 dataURL,生成后 canvas 是不需要继续存在的,因此在拿到 url 后就应该 destroy 掉它。
于是在我这么做了之后,情况好了很多,有更多的图片正常了,但并没有完全修复。原因很简单,因为刚开始的图片并发量太大了(顺带的就是 canvas 创建的并发量很大),尽管 canvas 用完后会销毁掉,但大部分没来得及等到销毁,内存限制就到了。所以还需要限制每次分页的数量或者干脆做成只在可视区域加载。我选择的是后者方案,因为瀑布流这种场景,严格一点来讲数量可以看做无限多,当某些极端的场景,用户刷了几万个资讯,滚动起来是可能会卡顿的。虚拟列表(virtual list)在这里既可以解决 canvas 太多的问题,也可以优化无限滚动性能。所以我需要虚拟列表的加持,由于技术栈是 React,所以这里我选择的是 react-virtualized 中的 Masonry。它只会渲染可视区域附近的元素,在无限滚动下也保持了性能的优异。
经过这些修改,并发的 canvas 创建已经不多了(永远保持在 10 个以内),用完的 canvas 也会被即时销毁,再也没有图片渲染失败的问题了。
加餐
前面我们留下了两个疑惑,1. Safari 对 canvas 的内存限制到底是多少。2. 浏览器渲染流程(渲染流水线)到底做了什么,滚动在该流程中处于什么位置。
canvas 内存限制
关于 1,我们可以写一个循环创建 canvas 的代码,每个 canvas 宽高各 512px,也就是一个 512x512 像素的纯白色图片(32 位),它占用内存 1MB。通过一步步试探我们就可以找出 chrome、Safari 等浏览器的限制是多少。下面看实际操作。
这里是实验代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1, minimum-scale=1, maximum-scale=1"
/>
<title>canvas limit</title>
</head>
<body>
<div>
<span>内存单位: MB</span>
<input type="number" id="number" />
</div>
<div>
<button id="create">创建</button>
</div>
<script>
// canvas放进该全局变量,防止GC
let canvasQueue = [];
// 创建 1MB canvas
const create1MCanvas = () => {
const size = 512;
const canvas = document.createElement("canvas");
canvas.width = size;
canvas.height = size;
const context = canvas.getContext("2d");
context.fillRect(0, 0, size, size);
return canvas;
};
// 创建 n x 1MB canvas
const createNMCanvas = (n) => {
for (let i = 0; i < n; i++) {
canvasQueue.push(create1MCanvas());
}
};
const input = document.querySelector("#number");
const button = document.querySelector("#create");
button.addEventListener("click", (event) => {
event.preventDefault();
const number = input.value;
if (!Number.isNaN(Number(number))) {
canvasQueue = [];
createNMCanvas(Number(number));
console.log(`创建${number}MB canvas成功`);
}
});
</script>
</body>
</html>操作系统是 macOS 10.15.7
Chrome
我们先在 chrome 实验一下每个 canvas 内存占用是否符合预期的 1MB,chrome 版本:101.0.4951.54(正式版本) (x86_64)
先记录一下初始 GPU 进程 内存占用(375MB)
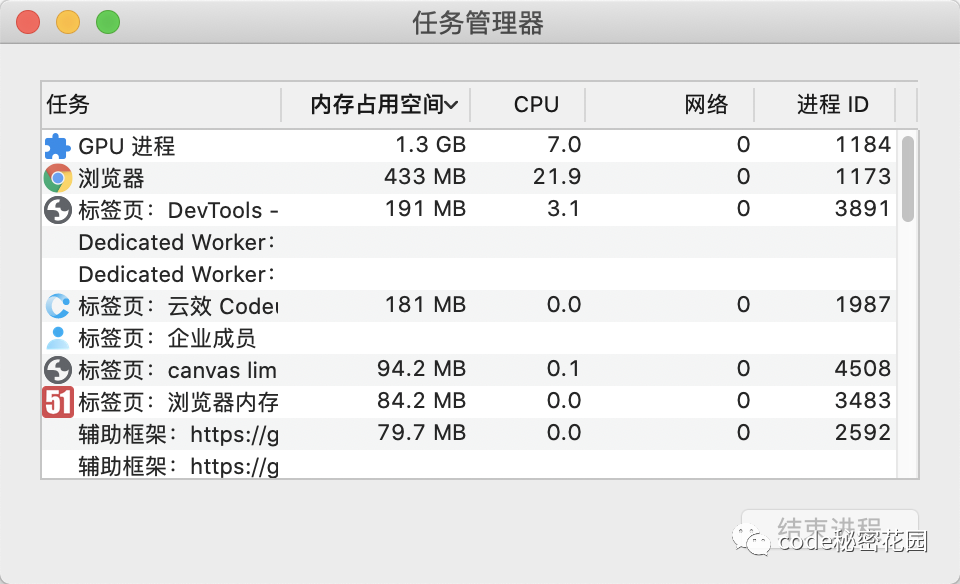
我们直接创建 10 万个 canvas,占用内存 10GB(PC 总内存是 16GB)
Safari
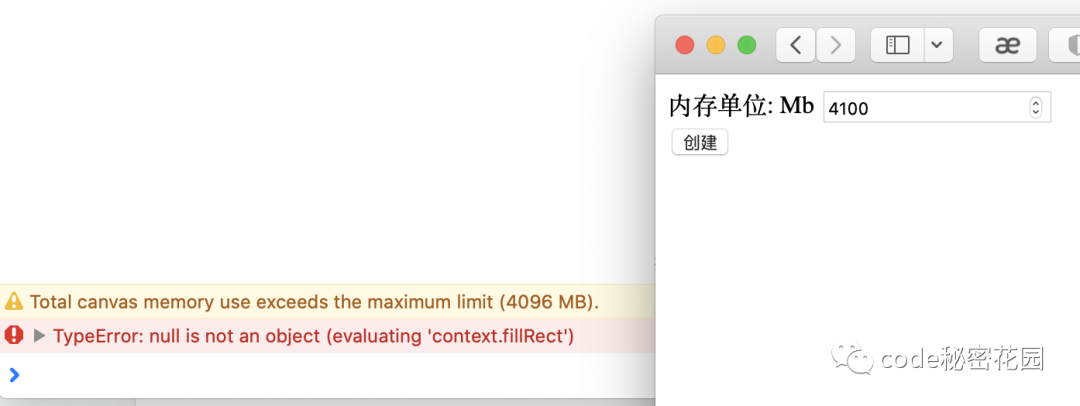
关闭 chrome 页面释放内存后,接着我们同样在 Safari 打开这个页面,Safari 版本 15.5 (15613.2.7.1.9, 15613)。
经过一步步增加内存占用,试出了 Safari 的最大限制(4096MB)
浏览器渲染流水线与滚动
首先简单讲一下 chrome 中渲染流水线的流程,一个 html 是怎么被处理成一个页面的。html 中 dom 部分生成 dom tree,css 部分生成 stylesheet,dom tree 在解析完后会等待 stylesheet 构建完再渲染。stylesheet 根据默认样式、样式继承、css 选择器规则、样式优先级等规则,找到对应的 dom 节点赋予它样式,形成 dom 结构+样式的 render tree。其中有些节点是不可见的(不是 opacity: 0,而是诸如 display: none 这样的),它们不会影响其他节点的位置,在渲染时不需要考虑,所以过滤掉这些节点之后生成 layout tree,layout tree 会根据节点之间的相互影响生成它们的位置信息(reflow 回流/重排)。
你以为到了 layout tree 这一步终于可以渲染了吗,还远没有。layout tree 会根据某些 css 属性分层,比如 position: absolute; position: fixed 等等。如果它们发生更新,不需要连带其他节点 reflow,所以分层有利于单独处理。然后每个图层会生成各自的绘制指令列表(repaint 重绘),很底层的命令,描述了每一个点每一条线如何绘制。
你以为生成了绘制命令终于可以渲染了吗,还远没有。它们会被交给合成层,顾名思义,它是负责将那些图层合并的。它并不会全量的处理整个页面,而是优先处理可见视口附近的图块,如果页面过于复杂,它还会先给出低分辨率的位图。图块的绘制命令会通过光栅化线程池交给 gpu 绘制。合成层拿到 gpu 绘制出来的位图后,将它们合成为一张位图,这就是当前页面。你觉得终于渲染完了吗,并没有。它会将位图交给浏览器进程里的 biz 组件,biz 组件会交给显示器的后缓冲区,当显示器需要显示下一帧之前,前后缓冲区交换,屏幕上终于展示出新渲染的页面帧。(这里补个小知识,requestAnimationFrame 的背后原理就是显示器发送了 sync 信号,渲染进程将 requestAnimationFrame 回调放进消息队列,从而实现了 js 未阻塞的情况下 requestAnimationFrame 可以随帧调用)
可以发现浏览器想渲染一帧页面要经过如此多的步骤,是不是真为它的性能捏一把汗,这也是 HTML 方便开发带来的代价。我们还可以看出整个流程中最昂贵的步骤就是 reflow 和 repaint 了,至于合成层那边主要是和 GPU 打交道,不会占用渲染线程(也就是执行 js 的线程),并且 GPU 本来就十分擅长处理图片,所以合成层的工作很快。
因此,性能优化的核心思路其实就是尽可能减少 reflow、repaint 的工作,尽可能多利用合成层的工作。比如 css 硬件加速,包括 transform3D、opacity、willchange 等。拿 transform3D 来说,其实它只是图层的位移、转换,并不影响其他图层,所以不会经过 reflow 和 repaint,直接在合成层处理,GPU 处理这种变换非常快。因此硬件加速技巧可以极大的优化 css 性能。
下面谈一下滚动操作带来的影响在渲染流水线中的处于什么位置。首先滚动可能会产生滚动条,它的突然出现影响了其他元素的布局位置,会触发 reflow 以及后面的所有流程。滚动过程中,前面说过合成层初始优先处理可见视口附近的图块,其他部分其实还没有处理,元素结构太复杂时滚动过快可能让合成层来不及处理,从而出现白屏区域。还有比如 position: fixed 的元素,会跟着滚动走,那么它也会在滚动中 repaint 的。
写在最后
为什么要学习原理(不管是编程领域还是其他领域),因为世间无穷的现象都可以用有限的原理解释,如果只停留于现象就会陷入经验主义。