当谈论协程时,我们在谈论什么
「什么是协程?」几乎是现在面试的必考题。一方面,Donald E. Knuth 说「子过程是协程的一种特殊表现形式」;另一方面,由于
coroutine的中文翻译「协程」中包含有「程」字,因此一般会拿来与「进程」、「线程」进行比较,称为「轻量级线程」。
- 第一部分介绍协程的历史;
- 第二部分主要是介绍函数调用和协作式多任务处理,虽然其他介绍协程的文章中也都讲解了函数调用,在本文中,我在构思如何进行分享时,特意使用汇编来实现函数调用 (汇编实现
main调用hello),为后面实现简单的协程库做好铺垫,而这正是理解协程切换的关键,推荐大家阅读;- 第三部在实现了一个简单的协程库后,通过对比来加深理解,然后介绍 libco hook 的实现;
- 第四部分介绍使用协程时需要注意的一些问题。
在本文中,我将试着去回答以下四个问题:
-
Q1 (Why): 为什么需要协程?
我们会一起回顾协程出现的历史背景,当时要解决什么问题;同时,现在是什么场景,需要使用协程来进行处理?为什么进程或者线程不能够很好地满足当下的使用场景?
-
Q2 (What): 到底什么是协程?
我们一直在谈论协程。由于协程中包含有「程」这个字眼,因此经常被拿来与进程线程进行对比,称协程为「用户态线程」;但又有人从协程实现的角度,说「协程是一种泛化的函数」。这就把我们给绕晕了。我们不禁要问,到底什么是协程?在本次分享中,我会试着进行回答。
-
Q3 (How): 怎么实现协程 (库)?
在回答了协程是什么之后,第三个问题就紧随而来,我们可以自己去实现一个简单的协程或者协程库吗?如果可以实现,那我们应该怎么实现呢?
-
Q4 (Usage): 使用协程时需要注意什么?
通过实际编码实现一个简单的协程库后,我们再来看 libco 的实现,就会清晰明了。我们会在第四部分介绍使用协程时需要注意的一些问题。
这就是我本次分享想要达成的目标 —— 回答这四个问题。
首先我们来看第一个问题,为什么需要协程?
Q1: 为什么需要协程?
在 1958 年,协程概念的提出者 Melvin Conway,想要为 COBOL 高级编程语言去实现一个 one-pass 的编译器。
Melvin Conway,康威定律 (Conway's Law) 的提出者,「设计系统的架构受制于产生这些设计的组织的沟通结构。」
这里的 pass,我们可以简单地理解为,一个 pass 就是对输入进行一次完整的扫描。也就是说他希望只扫描一次输入就实现编译,他通过借助协程来完成了这一工作。
为什么需要实现 one-pass 的 COBOL 编译器呢?目前找到的原因如下,来源 协程的历史,现在和未来:
- COBOL 语言的限制:COBOL 不是 LL-parse 型语法
- 使用磁带作为存储设备,磁带存储设备只支持顺序存储,不支持随机访问
依次执行编译步骤并依靠中间文件通信的设计是不现实的,各步骤必须同步前进。
在 Conway 的设计里,词法分析和语法分析是交织在一起。编译器的控制流在词法分析、语法分析之间来回进行切换:当词法分析读入足够多的 token,控制流就交给语法分析;当语法分析消化完所有 token,控制流就交给词法分析。有点类似于我们所熟知的生产者消费者模式。词法分析模块和语法分析模块需要分别独立维护自身的运行状态。他所构建的这种协同工作机制,需要参与者主动让出控制权,同时记住自身状态,以便在控制权返回时能够从上次让出的位置继续往下执行。
他的这些思想发表在 1963 年的论文 "[Design of a separable transition-diagram compiler] " 中,明确了协程的概念 —— “可以暂停和恢复执行”的函数。
我们知道 1960 年代出现进程的概念,那根据这里提到的年份,可以推断,协程的概念应该是早于进程的,那也就更早于线程。
但是协程不符合当时 (一直持续到 1990 年代) 以 C 语言为代表的命令式编程语言所崇尚的“自顶向下”的程序设计思想,因此对协程的使用和讨论一直都很低迷。
直到近些年,随着互联网的发展,尤其是移动互联网时代的到来,服务端对高并发的要求越来越高,也就是我们需要高性能的网络服务器,以 C10K 为代表,需要单机同时支持 1 万个并发连接,到 2013 年时候的单机要支持 1 千万并发连接 ([C10M 问题] ,[微信开源 libco:简单易用高性能的协程库] 中 libco 通过共享栈支持单机千万连接),协程开始重新进入视野。
如果要满足单机 1 千万的并发连接,我们先来看一下以下两种方案:
- 第一种是,多线程同步模型:
对应 C10K 中的 “[一个服务器线程服务一个客户端,使用同步阻塞 IO] ”,即预先创建出很多个处理线程,每个线程采用同步阻塞 IO 的方式串行处理请求,由操作系统通过线程切换来实现并发处理。这种方式开发者编码简单,但由于线程堆栈占用空间大,内存消耗太快,同时线程切换代价高,导致系统整体性能较差,现实开发中很少有人会使用这种模型。
- 第二种是,基于事件驱动的异步网络模型,以 Nginx 为代表,Nginx 将事件驱动+异步回调做到了极致:
对应 C10K 中的 “[一个线程服务多个客户端,使用非阻塞 IO 和就绪时通知机制] ”,这种方式由应用框架来实现事件驱动和状态切换,可以充分利用 CPU,性能较高,但因为处理都是基于回调,逻辑代码过于分散,导致代码开发效率不高,代码逻辑不易懂也容易出错。
那是否有一种方式,可以综合二者的优点,同时又不会引入太高的复杂度,就可以解决 C10K 乃至 C10M 的问题,解决好服务器充斥着的大量的 IO 请求的问题呢?
也就是,我既要「同步编程风格」,能够让业务开发人员很便捷地去开发业务逻辑代码,同时能够达到「异步回调模型的性能」。
那就是协程大展拳脚的场景了 (协程 + IO Hook)。那什么是协程呢?
“其实不应该把协程和多线程做类比,协程更多的是取代异步状态机的数据结构,如果明确这点,就能够清晰使用场景了。” —— from libco 的实现者
Q2: 到底什么是协程?
首先我们来看一下维基百科对协程的定义:
Coroutines are computer program components that generalize subroutines for non-preemptive multitasking, by allowing execution to be suspended and resumed. —— from Wikipieda
协程是一类程序组件,它是对子过程概念的泛化,并且是属于非抢占的多任务处理。

co-routine 的两个部分:
- 泛化的子过程 (generalize subroutines),也就是说协程是泛化的函数 (subroutines, alias procedures, functions, methods, handlers etc) -- 那协程在哪些方面,相较函数更为泛化呢?这里也有提到,就是说协程可以暂停和恢复执行的 (allowing execution to be suspended and resumed),与我们前面讲到的 Conway 对协程概念的定义是一致的;
- 非抢占的多任务处理 (non-preemptive multitasking) -- 这里说明了协程的作用,也就是协作式多任务处理 (cooperative multitasking),同时也点明了协程的特点,协作,因此需主动让出 CPU。
CSAPP Section 3.7 Procedures. "Procedures come in many guises in different programming languages—functions, methods, subroutines, handlers, and so on—but they all share a general set of features."
接下来我们展开对这两个概念的讲解:函数和多任务处理,并且讨论这两个概念与协程的关系。
函数与函数调用
函数,是我们日常开发中最常用到的一种封装手段,它将一组实现特定功能的代码段封装起来,接受一些输入参数,返回一些输出参数。
例如,下面这段简短的 代码片段 (跳转过去看看汇编,AT&T 汇编语法),main 调用 hello,hello 调用 world:
int world(int num) {
// ....
return 42;
}
int hello(int num) {
int x = 32;
int* y = &x;
// ....
return world(num);
}
int main() {
int num = 5;
hello(num); // <--·
return 0;
}函数调用的关键点 (CSAPP Section 3.7 Procedures):
-
控制权转移
-
函数调用
-
函数返回
-
数据传递
-
函数入参
-
函数返回值
-
内存的分配和释放
需要遵循 calling conventions (ABI),[System V ABI AMD64, pdf] 。
说起来比较抽象,我们直接看看对应的汇编代码:
-
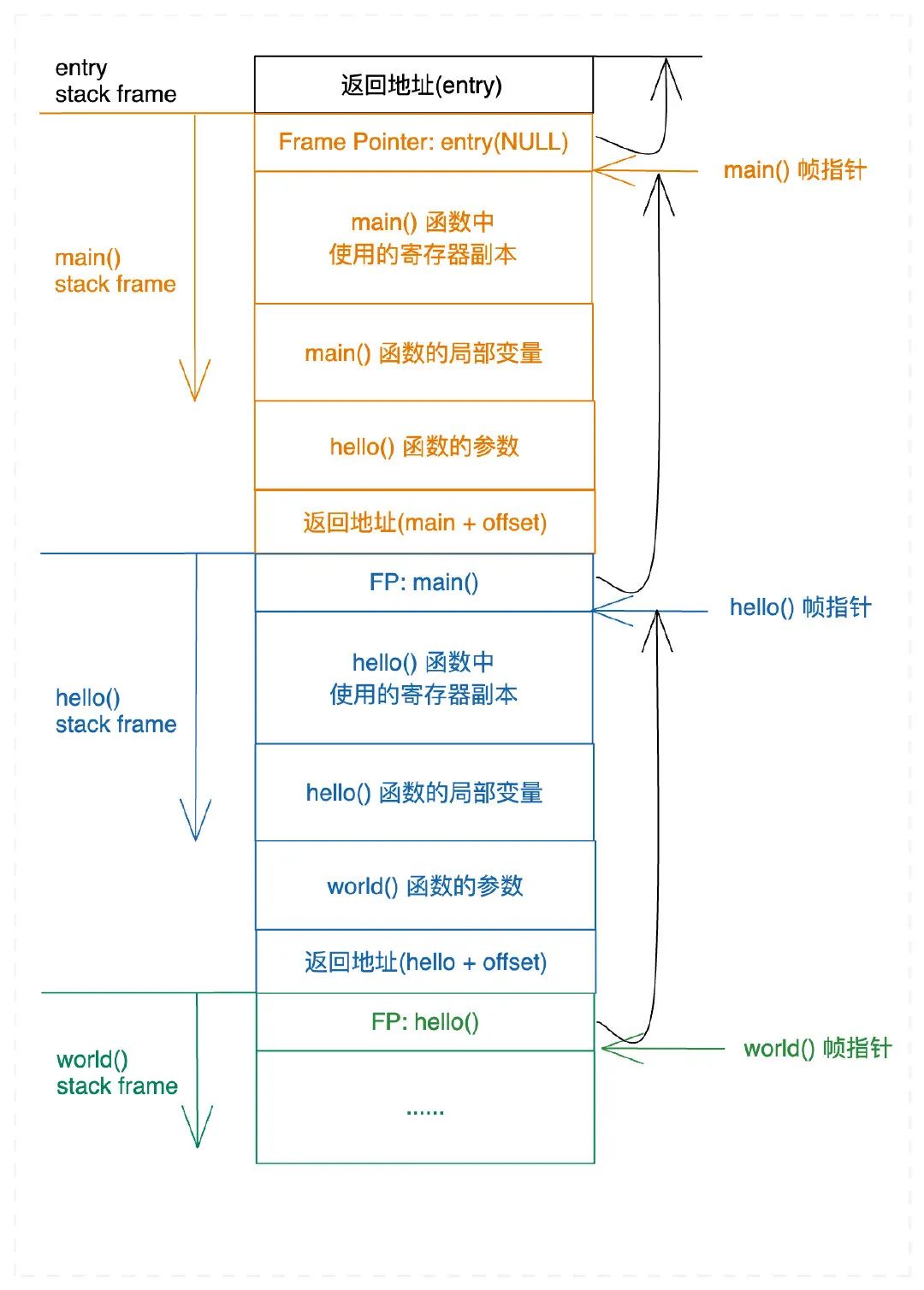
main、hello、world三个函数,进入时,都执行了相同的一段汇编代码pushq %rbp movq %rsp, %rbp将
rbp压栈,然后将rsp的值设置到rbp。以
main调用hello为例,这两行汇编就是将main的栈基址保存到栈中,然后更新rbp指向栈顶,也就是rbp此时就是hello的栈基址了;同理,hello调用world时,也是将hello的栈基址压栈,然后切换到world栈基址。这样就形成了一个栈帧的链式结构。这样有什么好处呢?让我们继续往下看。 -
main、hello、world三个函数返回时,也是一段相同逻辑的汇编代码popq %rbp将当前栈顶指针
rsp指向的内容pop到rbp。以
world为例,由于它没有在栈上进行内存分配,此时rsp就是指向绿色标注的这里,pop出栈顶的内容到rbp,这样rbp就指到了hello的栈基址了。这样就动态地维护了函数调用栈帧。
因此,我们说,函数调用就是创建栈帧,函数返回就是弹出栈帧。
-
同样的,以
main调用hello为例call hello将
call hello后的下一条指令地址保存到栈上,然后执行一个跳转指令 (修改eip寄存器的值,表示当前正在执行的指令地址)。
这样我们就明白了,要调用一个函数,主要就是两个比较重要的事项:
- 跳转到对应的函数入口执行,需要修改
eip; - 函数执行需要使用栈帧维护调用关系,保存一些其他信息,因此需要分配栈帧空间,并修改
rsp指向。为什么这里我们没有感觉到rsp呢?是因为这里栈是连续的,push和pop操作,将信息保存到栈中或弹出栈中数据时,会同步修改栈顶指针rsp。
其他的函数入参和返回值,直接按照 ABI 规范来就可以了。
实际使用函数时,我们不用太在意这里的细节。但理解这些细节,可以帮助我们更好的理解协程。
学习这一部分的内容,还会有一些额外收获:
- 为什么函数参数最好控制在 6 个参数内,因为 x86-64 的函数调用,前 6 个参数是通过寄存器传递的,多余的参数通过入栈传递;
- 不要直接传递大对象,使用指针或引用
- ...
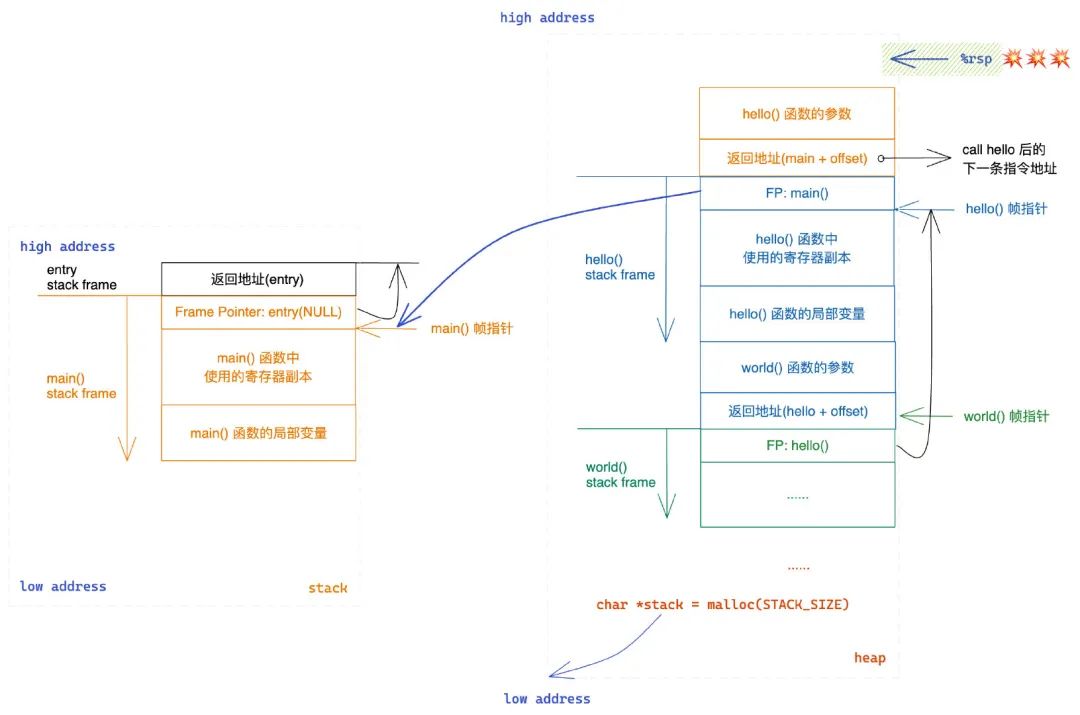
这里很多事情都是编译器帮我们干了,如果我们要自己动手,使用汇编实现 main 调用 hello,我们应该怎么做呢?
使用汇编实现函数调用
只需要维护好前面提到的两个比较重要的寄存器 rip 和 rsp 就可以了。
首先,要调用 hello,就包含有控制权的转移,需要修改 rip,这个比较简单,直接 call hello 就可以了。
其次控制权转移到 hello 后,函数开始执行,需要为 hello 分配好调用栈,直接使用 malloc 在堆上分配。需要注意 malloc 返回的地址是低地址,需要加上分配的内存大小获取得到高地址。这是由于我们要在动态分配的这块内存上模拟栈的行为,而在 x86-64 中栈底是高地址,栈从高地址往低地址进行增长。
这样我们的栈帧就不是连续的了,main 的栈帧在栈上,hello 的栈帧在堆上。但其实这是没有影响的,只需要能够维护好栈帧的链式关系就可以了。在进入 hello 时,和之前一样会保存好 main 的 rbp,因此我们不需要额外关注链式结构。
我们只需要手动维护 rsp 就可以了。
用一段伪 (汇编) 代码描述一下,将 malloc 分配的内存,其高地址设置到 rsp 中,将参数设置到 rdi 中,call hello 进行调用。可以在前后做一些操作,将后续会用到的数据保存到栈中,后面 pop 出来继续使用。
# store sth, for later use --> 序言 (prologue)
# store old `%rsp`
movq hello_stack_sp, %rsp # 设置 `hello` 调用栈 !!!
movq $0x5, %rdi # 设置入参
call hello # 1) 保存返回地址
# 2) 跳转到 `hello` 执行
# restore and resume --> 后记 (epilogue)
# resume old `%rsp`借助下面的图方便进行理解。记住,这里是理解协程的关键。
从这里我们也可以看出,其实函数调用栈就是一块内存,它不一定需要连续 ("[the stack is a simple block of memory] ")。
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
// 调用栈太小的话,在执行函数调用时会报错 (printf)
// fish: Job 1, './call-hello' terminated by signal SIGSEGV (Address boundary
// error)
#define STACK_SIZE (64 * 1024) // <-- caution !!!
uint64_t world(uint64_t num) {
printf("hello from world, %ld\n", num);
return 42;
}
uint64_t hello(uint64_t num) { return world(num); }
int main() {
uint64_t num = 5, res = 0;
char *stack = malloc(STACK_SIZE); // 分配调用栈 !!!
char *sp = stack + STACK_SIZE;
asm volatile("movq %%rcx, 0(%1)\n\t"
"movq %1, %%rsp\n\t"
"movq %3, %%rdi\n\t"
"call *%2\n\t"
: "=r"(res) /* output */
: "b"((uintptr_t)sp - 16), /* input */
"d"((uintptr_t)hello),
"a"((uintptr_t)num));
asm volatile("movq 0(%%rsp), %%rcx" : :); // 这里的 restore 可以删除掉
printf("num = %ld, res = %ld\n", num, res);
return 0;
}
// hello from world, 5
// num = 5, res = 42主要关注 main 函数中调用 hello 的这段内联汇编,查看其对应的汇编代码 ([代码片段 (跳转过去看看汇编,同时本地用 gdb 调试一下)] ),与直接调用 hello(5) 的汇编代码基本一致。这里我们未实现 restore old rsp,需要注意。
本质就是,实现控制权的转移,同时在程序运行时一直满足 ABI 的要求。
- [GCC 内联汇编] ,特别注意 ❗️:x86-64 要求调用栈按照 16 字节对齐 (当然这就是 ABI 的要求了,我们需要查询手册)
讲了这么多关于函数和函数调用的知识点,基本上都是我们熟知的。大家可能会纳闷,函数调用和我们今天要讲的协程有什么关系呢?
前面我们提到「协程是泛化的函数」,其实这话是高德纳说的:
Subroutines are special cases of more general program components, called coroutines. In contrast to the unsymmetric relationship between a main routine and a subroutine, there is complete symmetry between coroutines, which call on each other.
-- Donald E. Knuth, Art of Computer Programming - Volume 1 (Fundamental Algorithms), 1.4.2. Coroutines
与函数相比,协程要更通用一些,即函数是协程的一种特殊情况。
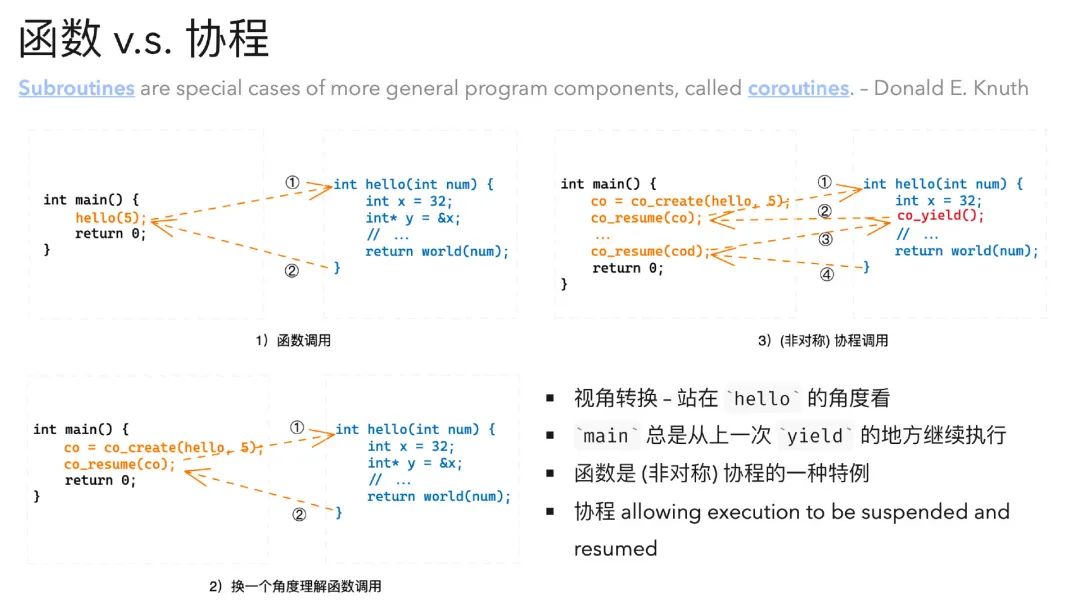
main 函数调用 hello,hello 再调用 world,会形成一个函数调用栈。当 world 执行完毕后,返回 hello,hello 继续执行,hello 执行完毕后,返回 main,main 继续执行,直至执行完成。
这都是站在 main 函数的角度在理解。
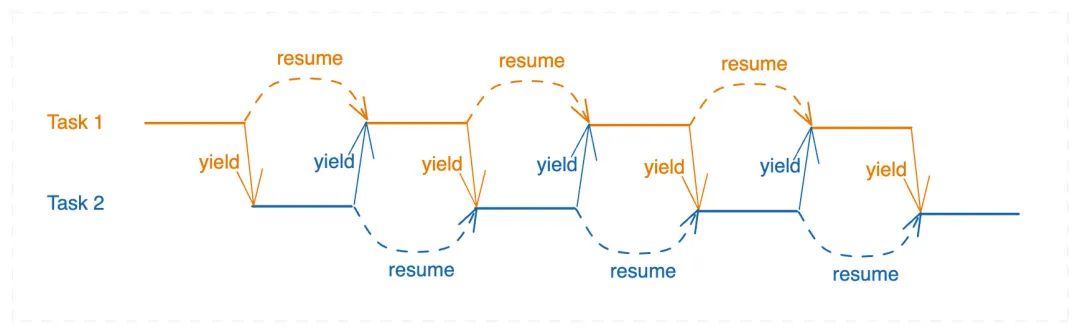
我们可以试着换一个视角,站在 hello 函数的角度来看看 (左下角的这张图)。
就可以这么理解 —— main``yield 主动让出执行权,resume``hello,hello 获得执行权,开始执行,执行完成后 hello``yield 让出执行权 (return 语句),resume``main 函数继续执行。这样来看,main 总是从上一次 yield 的地方继续向下执行。
但协程又与函数调用有些不同,协程能够多次被暂停和恢复 (右上角的这张图)。hello 可以 yield 主动让出控制权 (这就是与普通函数调用不一样的地方,普通函数只能在 return 时 yield 让出控制权,不会再次恢复执行),再次唤醒时,hello 从最近一次 yield 的地方继续往下执行。
我们只需要在 hello``yield 时保存执行的上下文,后面重新获取 CPU 控制权时,恢复保存的上下文。如何实现控制流的主动让出和返回 —— 这个比较容易实现,类比 main 通过汇编调用 hello,维护好 rsp 和 rip 等寄存器就可以了。会在第三部分实现一个简单的协程时,详细进行说明。
回到函数与协程,此时,我们可以说,函数是协程的一种特例,协程切换和函数调用,二者的操作大体相同。
接下来,我们继续来看一下 coroutine 的第二个关键点,多任务处理。
多任务处理:并发地执行多个任务的能力
多任务是操作系统提供的特性,指能够 并发 地执行多个任务。比如现在我使用 chrome 在进行投影,同时后台还运行着微信、打开着终端。这样看上去好像多个任务是在并行运行着,实际上,一个 CPU 核心在同一时间只能执行一条指令。图示中一个矩形框表示一个 CPU 核心。
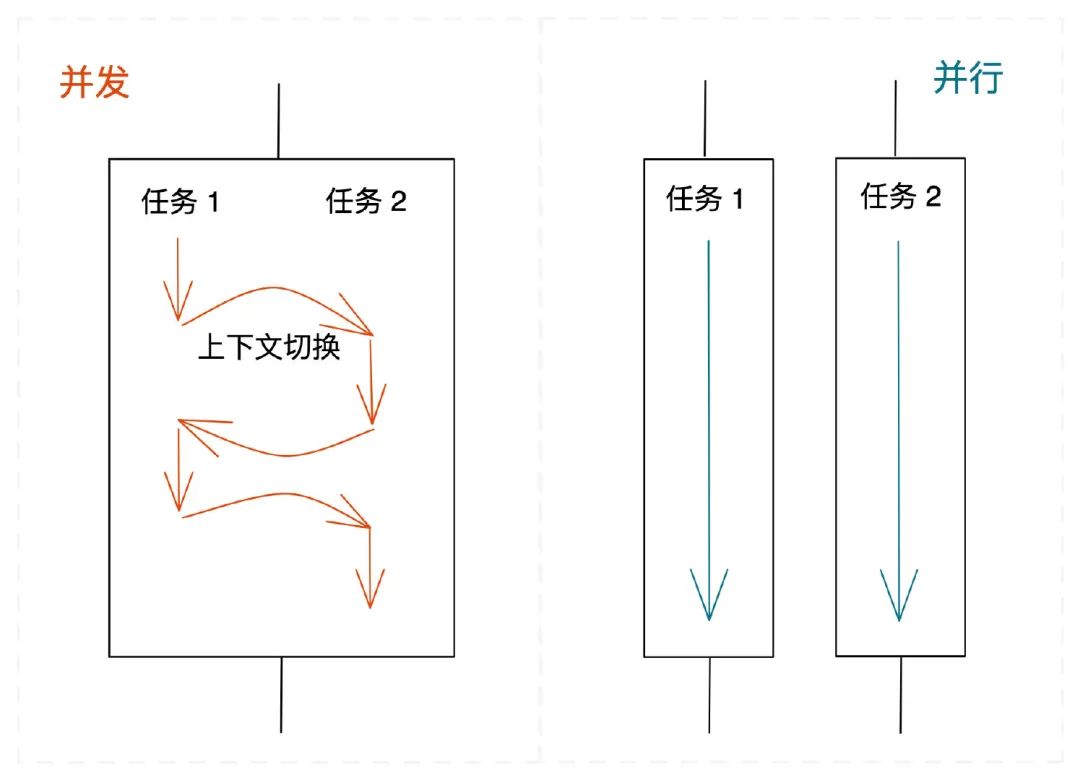
那真实的并行是怎么样的呢?需要有多个 CPU 核心,每一个核心负责处理一个任务,这样在同一个时间片下就会同时有多条指令在并行运行着 (每个核心对应一条指令),不需要在任务之间进行上下文切换。
Rob Pike,也就是 Golang 语言的创始人之一,在 2012 年的一个分享 (Concurrency is not Parallelism, Rob Pike, 2012, slide) 中就专门讨论了并发和并行的区别,很直观地解释了二者的区别:
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once. -- Rob Pike
并发是一种 同时处理 很多事情的能力,并行是一种 同时执行 很多事情的手段。
我们把要做的事情拆分成多个独立的任务进行处理,这是并发的能力。在多核多 CPU 的机器上同时运行这些任务,是并行的手段。可以说,并发是为并行赋能。当我们具备了并发的能力,并行就是水到渠成的事情。
所以我们平时都谈论高并发处理,而不会说高并行处理(这是高性能计算中的内容)。
今天,在这里,我们主要讨论的是单核 CPU 上的多任务处理,涉及到几个问题:
- 任务是什么,怎样抽象任务这样一个概念?
- 多个任务之间需要进行切换,把当前任务的上下文先保存起来,把另一个任务的上下文恢复,那么任务的上下文都包含哪些东西呢,如何进行上下文的保存和恢复呢?
- 什么情况下进行任务切换?
下面我们来看一下任务包含哪几个层次的抽象。
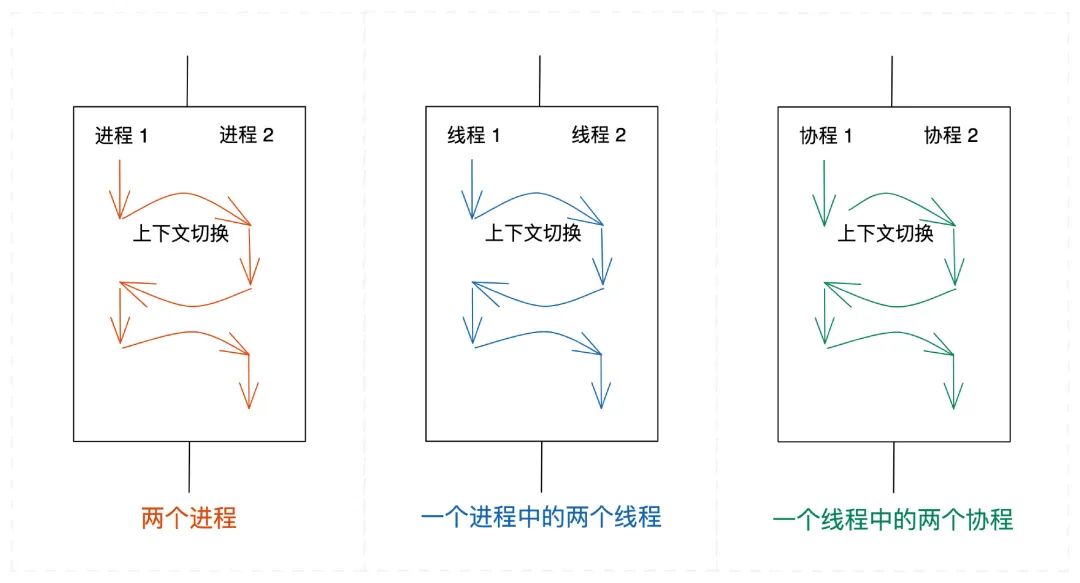
任务抽象:进程、线程、协程
从今天的实现看,任务的抽象并不唯一。
| 任务抽象 | 上下文 |
|---|---|
| 进程 | PCB |
| 线程 | TCB |
| 协程 | use-defined |
从任务的抽象层级来看:对于进程,其上下文保存在进程控制块中;对于线程,其上下文保存在线程控制块中;而对于协程,上下文信息由程序员自己进行维护。
但如果我们换一个角度,从 CPU 的角度来看,这里所说的任务的上下文表示什么呢?我们都知道,冯诺依曼体系结构计算机,执行程序主要依赖的是内置存储:寄存器和内存,这就构成了程序运行的上下文 (context)。
寄存器的数量很少且可以枚举,我们直接通过寄存器名进行数据的存取。在将 CPU 的执行权从任务 1 切换到任务 2 时,要把任务 1 所使用到的寄存器都保存起来 (以便后续轮到任务 1 继续执行时进行恢复),并且寄存器的值恢复到任务 2 上一次执行时的值,然后才将执行权交给任务 2。
再看内存,不同的任务可以有不同的地址空间,通过不同的地址映射表来体现。如何切换地址映射表,也是修改寄存器。
所以,任务的上下文就是一堆寄存器的值。要切换任务,只需要保存和恢复一堆寄存器的值就可以了。针对进程、线程、协程,都是如此。
这样,我们就回答了上一页中,什么是任务以及任务的上下文是什么,如何进行保存和恢复。
接下来我们来看上一页中的第三个问题,任务在什么时候进行切换?一个任务占用着 CPU 核心正在运行着,有两种方式让它放弃对 CPU 的控制,一个是主动,一个是被动。
主动和被动,在计算机中有它的专有用词,抢占式和协作式。
抢占式 (preemptive) 是被动的,由操作系统来控制任务切换的时机。
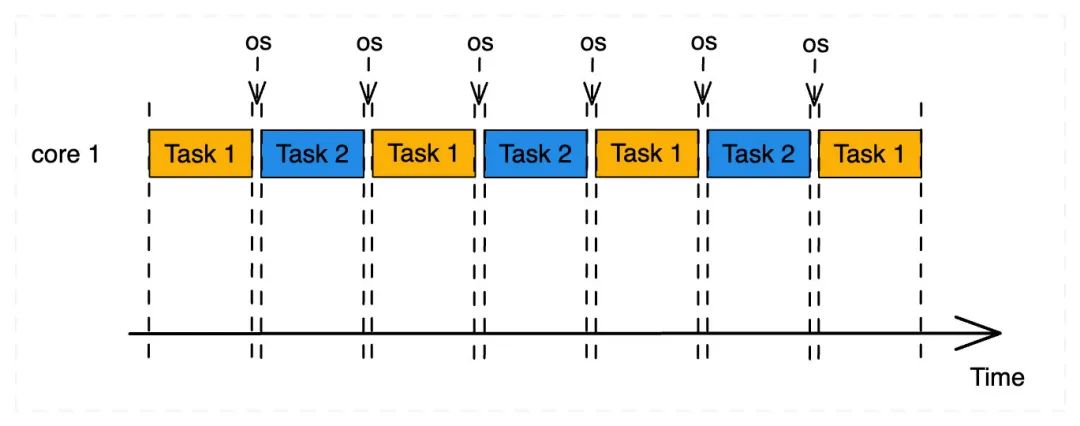
我们可以看到,抢占式多任务中操作系统就是“老大”,操作系统能够完全控制每个任务的执行时间,从而保证每个任务能够获得一个相对公平的 CPU 时间片,使得运行不可靠的用户态程序成为可能,例如 while (true) { } 这样的死循环。
抢占式的问题也很明显,因为有操作系统的参与,每次进行任务切换,都会从用户态切换到内核态,还需要保存任务的上下文信息,因此上下文切换开销比较大。同时由于每个任务都有单独的栈空间,在启动过多任务时,内存占用大,会限制系统支持运行的任务数量。
与抢占式多任务强制性地暂停任务的执行不同,协作式 (cooperative) 多任务允许任务一直运行,直至该任务主动放弃 CPU 的执行权。
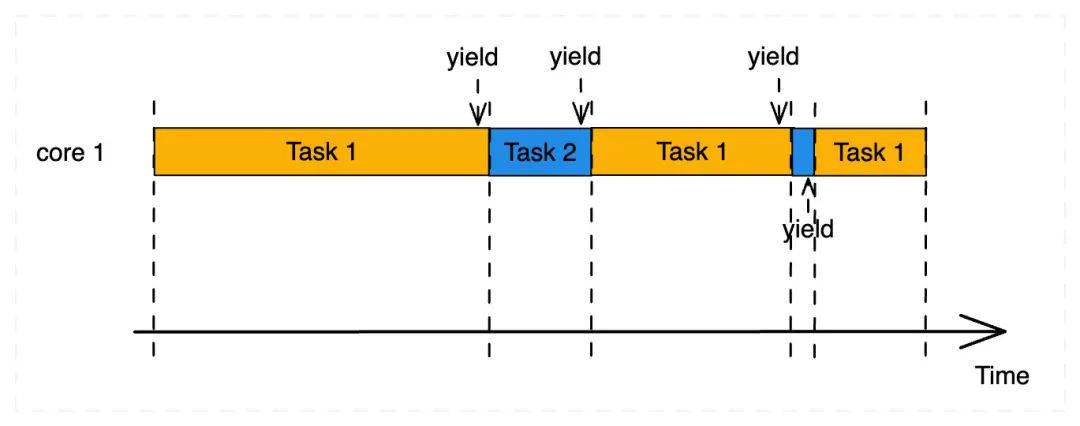
实际上,调度方式并无高下,完全取决于应用场景:
- 抢占式多任务需要 CPU 硬件的支持,操作系统运行在内核态 level 0,而用户程序运行在用户态 level 3,因此操作系统可以剥夺进程的执行权限,抢占控制流,天然适合与用户有交互的场景,因为调度器可以优先保证对用户交互;
- 协同式多任务适用于那些没有处理器权限支持的场景,这些场景包含资源受限的嵌入式系统和实时系统。在这些系统中,程序均以协程的方式运行。调度器负责控制流的让出和恢复。通过协程的模型,无需硬件支持,我们就可以在一个“简陋”的处理器上实现一个多任务的系统。我们见到的许多智能设备,如运动手环,基于硬件限制,都是采用协同调度的架构。
维基百科中关于 co-routine 的两个关键概念,我们就已经全部分析清楚了
- 函数,协程就是一个函数,只是它支持多次的暂停和恢复执行,需要我们自己手动维护调用栈和其他的一些信息;
- 协作式多任务处理,协程主动让出 CPU,天然就支持协作式多任务。
那现在,我们可以说什么是协程了吗?
那协程到底是什么呢?
当然,也有人认为只有 goroutine 那样的才是完备的协程,认为一个完备的协程库就是一个用户态的操作系统,而协程就是用户态操作系统里面的 “进程” (from 许式伟的架构课)。
本次分享中,我们还不会涉及到这么复杂的内容。控制流的主动让出和恢复,就是我们理解协程的关键了。
知道了协程是什么,那我们如何实现一个协程呢?
Q3: 怎么实现协程 (库)?
这部分内容实现一个简单的协程库,来源于南京大学《操作系统:设计与实现》 - M2: 协程库 (libco)。
在分享中,进行了详细的代码实现解释,基于 jyy 老师的课程要求,这里不直接在文章中贴对应的实现代码了,大家可以点击 南京大学《操作系统:设计与实现》 - M2: 协程库 (libco),jyy 老师给到了详细的实现 notes,我从里面学习到了很多,相信你也会和我有一样的感受。实现的过程中,如果有疑问,可以私信我进行交流。
假设你已经完成了实验 (在阅读本文的时候,还没有做实验,也没关心,不影响后续内容的理解),让我们一起来做一个技术总结。
从 0 实现一个简单的协程库:小结
| 关注点 | 当前实现 | 其他实现 |
|---|---|---|
| 协程上下文切换 | setjmp / longjmp,配合汇编 stack_switch_call |
- 汇编实现 → libco 的 [coctx_swap.S] - ucontext 簇函数 → 云风的 [coroutine] - Boost 库,boost.coroutine / boost.context |
| (有栈) 协程 | 独立栈,每个协程有单独的调用栈 | - libco 同时支持独立栈和共享栈 |
| 独立栈内存管理 | malloc / free,自动回收内存 | - 提供 co_free,调用方需手动释放内存 → libco |
| 协程栈溢出检测 | 不支持 | - mprotect 保护页 → libco |
| yield 后的控制流 | 对称协程,调度器选择一个可运行的协程 | - 非对称协程,只能返回调用者 → libco |
| 协程调度 | 1:N 调度 (单线程调度),双向链表管理,round-robin | - 1:N 专门的调度器 → libco - M:N 调度 (多线程调度),支持 [work stealing] → Goroutine、Rust Tokio |
按照表格从上往下:
-
实验中我们使用
setjmp/longjmp,配合汇编stack_switch_call(也就是开始部分,使用汇编实现main调用hello的那部分内联汇编),来实现协程的上下文切换。这里会有其他一些实现,例如 libco 是直接汇编实现切换,云风实现的 lua 风格的 coroutine 使用的是ucontext族函数,另外还可以使用 boost 库提供的协程实现; -
为了讲解的简单,我们选择为每一个协程单独分配独立的调用栈,为有栈协程,且是独立栈,libco 是同时支持独立栈和共享栈的。
-
共享栈意思就是,每个协程都有独立的状态栈,一个线程中的多个协程共享一个调用栈。由于这些协程中同时只会有一个协程处于活跃状态,当前活跃的协程可以临时使用调用栈。当此协程被挂起时,将调用栈中的状态保存到自身的状态栈;当协程恢复运行时,将状态栈再拷贝到调用栈。实践中通常设置较大的调用栈和较小的状态栈,来达到节省内存的目的。
-
在内存管理方面,直接使用
malloc和free进行内存的分配和释放,配合co_wait和函数标识定义全局析构函数,实现自动的内存回收。libco 的实现,需要调用方手动去释放内存; -
在实际的业务场景中,有时可能会栈溢出,libco 提供了保护页机制,也就是在分配函数调用栈时,同时分配保护页,可以检测协程栈溢出。在我们的简单实现中,没有实现;
-
对于
co_yield后的协程调度,按控制传递机制分为两类: -
对称协程(Symmetric Coroutine):和线程类似,协程之间是对等关系,多个协程之间可以任意跳转
-
非对称协程(Asymmetric Coroutine):协程之间存在调用和被调用关系,如协程 A 调用/恢复协程 B,协程 B 挂起/返回时只能回到协程 A,libco 就是非对程的协程实现,调用层级可以 128 次
-
最后是协程调度,我们的实现中比较简单,使用双向链表管理协程,round-robin,单线程调度 (
1:N),使用 1 个线程调度 N 个协程;libco 使用专门的调度器,同时还有一些实现,例如 goroutine,或者 rust 的协程实现,支持多线程调度 (M:N),使用 M 个线程调度 N 个协程,同时还支持 work stealing,就是说线程本地的就绪队列为空,可以去其他线程的就绪队列上抢待处理的协程任务来进行执行
更详细的介绍,可以看 [微信终端自研 C++协程框架的设计与实现]
通过比较我们实现的协程,与其他的一些协程实现,可以加深我们对协程的理解。
但这里,我们可能还有其他的一些问题,还可以利用协程做什么呢?
还可以做什么?
- Hook 系统调用,libco 开创性地将协程与 socket hook 相结合,方便业务代码直接进行异步化协程改造,而不需要修改系统调用函数;
- 编程语言原生支持协程,[Lua] 、[C++20] 、[Rust] 、[Goroutine] 等;
- 无栈协程,C++20、Rust,由编译器来完成状态机的维护;
- 完整的生态:
- 协程间通信:共享内存,[Channel] ;
- 协程锁 -- 类比
Mutex; - 协程本地存储 (Coroutine Specific) -- 类比线程本地存储
man 3 pthread_getspecific; - ...
今天限于时间和篇幅,先主要讲解一下 libco 的 IO hook,如果大家多这里其他的点也很感兴趣可以告诉我,我看看可以再补充一下内容,作为协程分享 2.0。
接下来我们看看 libco 的 IO hook。
libco Hook
先来看一个 [echo server] 的例子,在 accept 、recv、send 都会 [阻塞] ,整个进程都会暂停执行,等待 IO 完成。
// echo server, 删除了 setup 和 error handling 的代码
int main(int argc, char *argv[]) {
int server_fd, client_fd;
struct sockaddr_in server, client;
char buf[BUF_SIZE];
server_fd = socket(AF_INET, SOCK_STREAM, 0);
bind(server_fd, (struct sockaddr *)&server, sizeof(server));
listen(server_fd, 1024);
while (1) {
socklen_t client_len = sizeof(client);
client_fd = accept(server_fd, (struct sockaddr *) &client, &client_len); // block
while (1) {
int read = recv(client_fd, buf, BUF_SIZE, 0); // block
send(client_fd, buf, read, 0); // block
}
}
return 0;
}很明显,如果这段代码直接出现在 svrkit 框架代码中,那即使配合使用 libco 也救不回来 (假设 libco 未实现 hook socket),一个阻塞操作,整个服务就暂停了。
很简单的一个想法,非阻塞 IO + IO 多路复用 (epoll 或者 kqueue 等),也就是我们第一部分讲解到的,但这里我们将协程也添加进来。
以 recv() 接收数据为例,在真实的读取数据前,执行操作:
- 建立
client_fd到当前协程的映射; - 将
client_fd添加到epoll()的EPOLLIN事件中; co_yield()主动让出 CPU;epoll()返回,根据fd得到对应的协程,读取数据,继续后续处理。
就这么简单,如 libco 的实现者所说 “设计应该是简单的,非常简单”。
那 libco 是如何实现 Hook 的呢?
libco 使用 [dlysm] 对系统调用进行了 Hook,包含一些几类函数,[完整列表] 大家可以点击这里的链接,跳转过去直接查看代码:
socket族函数- IO 函数
poll函数- 环境变量函数
- host 函数
如何用 dlysm (man 3 recv) 对系统调用进行 Hook 呢?按照以下四个步骤:
#include <sys/socket.h>
ssize_t recv(int socket, void *buffer, size_t length, int flags);
// `basic/colib/co_hook_sys_call.h` 中与系统调用签名相同的函数,例如 `recv()`
typedef ssize_t (*recv_pfn_t)(int socket, void* buffer, size_t length, int flags);- 声明并实现一个与系统调用签名相同的函数,例如
recv(); - 编译为动态链接库
librecvhook.so; - 应用程序使用
recv(),在加载动态库时指定顺序,librecvhook.so > libc.so; - 这样应用程序就会调用步骤 1 中实现的
recv()。
但我们最终还是要调用系统调用 recv 的,那如何实现直接调用系统调用呢?
将 dlsym 的第一个参数指定 RTLD_NEXT - 这样就会跳过找到的第一个 symbol 地址,获取该 symbol 对应的第二个地址,这样就获取得到了真实的系统调用入口地址。
// 使用 `dlsym` 查找动态库中 `recv` symbol 的地址
// `RTLD_NEXT` - 跳过找到的第一个地址,获取该 symbol 对应的第二个地址
static recv_pfn_t g_sys_recv_func = (recv_pfn_t)dlsym(RTLD_NEXT, "recv");libco 是如何将 dlsym hook 系统调用与协程有机结合起来的呢?
来看代码,libco 的 recv 实现。
- 首先,获取系统调用的
recv()的符号地址; - 然后,判断当前协程是否开启了 Hook,如果没有开启,则使用系统调用;libco 中,所有协程初始化时,Hook 都是没有开启的;
- 根据 fd 获取对应的 rpc 信息,包含协程的结构体信息,也就是前面提到的 fd 与协程的映射关系;
- 如果没有开启非阻塞,直接调用系统调用;
- 设置超时时间,通过
poll等待读完成(poll也被 hook 了),这里会切换到父协程,父协程会在读事件/超时事件触发时回到该协程; - 有数据了,或者超时,协程恢复执行,读取数据,调用的是系统调用,会判断是否读取成功;
- 这就是一个同步的写法了,看起来就很清爽。
ssize_t recv(int socket, void* buffer, size_t length, int flags) {
// 获取系统调用的 `recv()` 的符号地址
HOOK_SYS_FUNC(recv); // <-- 1) here
// 判断当前协程是否开启了 Hook,如果没有开启,则使用系统调用;libco 中,所有协程初始化时,Hook 都是没有开启的
if (!co_is_enable_sys_hook()) {
return g_sys_recv_func(socket, buffer, length, flags);
}
// 根据 fd 获取对应的 rpc 信息,包含协程的结构体信息
rpchook_t* lp = get_by_fd(socket); // <-- 2) here
// 如果没有开启非阻塞,直接调用系统调用
if (!lp || (O_NONBLOCK & lp->user_flag)) {
return g_sys_recv_func(socket, buffer, length, flags);
}
int timeout = (lp->read_timeout.tv_sec * 1000) + (lp->read_timeout.tv_usec / 1000); // 超时时间
// 通过 `poll` 等待读完成,这里会切换到父协程,父协程会在读事件/超时事件触发时回到该协程
struct pollfd pf = {0};
pf.fd = socket;
pf.events = (POLLIN | POLLERR | POLLHUP);
poll(&pf, 1, timeout); // `poll` 也被 hook 了 // <-- 3) yield here !!!
// 有数据了,或者超时,读取数据,调用的是系统调用,会判断是否读取成功
ssize_t readret = g_sys_recv_func(socket, buffer, length, flags); // <-- 4) here
if (readret < 0) {
return readret;
}
return readret;
}libco 源码,[github repo]
至此,我们就讲完了协程以及 libco 的原理部分了。
那理解这些,对我们使用协程有什么用呢?这就进入了第四部分。
Q4: 说了这么多,在工作中有什么用呢?
Case 1: 协程栈溢出
libco 的协程栈,是调用 malloc 分配的堆上内存,这里称为「栈」,只是一种惯例的称谓。
libco 协程栈的内存分配代码,[co_create_env] :
struct stCoRoutine_t* co_create_env(/* ... */) {
// ...
// 协程栈默认 128KB,最大 8MB
if (at.stack_size <= 0) {
at.stack_size = 128 * 1024;
} else if (at.stack_size > 1024 * 1024 * 8) {
at.stack_size = 1024 * 1024 * 8;
}
// ...
stCoRoutine_t* lp = (stCoRoutine_t*)malloc(sizeof(stCoRoutine_t));
stStackMem_t* stack_mem = NULL;
stack_mem = co_alloc_stackmem(at.stack_size);
lp->stack_mem = stack_mem;
lp->ctx.ss_sp = stack_mem->stack_buffer;
lp->ctx.ss_size = at.stack_size;
return lp;
}
stStackMem_t* co_alloc_stackmem(unsigned int stack_size) {
stStackMem_t* stack_mem = (stStackMem_t*)malloc(sizeof(stStackMem_t));
stack_mem->occupy_co= NULL;
stack_mem->stack_size = stack_size;
stack_mem->stack_buffer = (char*)malloc(stack_size); // <-- here
stack_mem->stack_bp = stack_mem->stack_buffer + stack_size;
return stack_mem;
}协程栈默认 128KB,最大 8MB。
在进行业务开发时,如果直接在协程栈上分配一块大内存,就直接爆栈了。
int send() {
char raw_buffer[400000 + 8]; // 400KB
// ... do sth with raw_buffer
}Case 2: 在协程中使用线程锁,yield 前未释放
看下面这段代码片段:
// 示例 1: 显式使用线程锁,`co_yield` 协程切换时未释放该线程锁
std::mutex g_mutex;
void hello() {
const std::lock_guard<std::mutex> lock(g_mutex);
co_yield(); // 请求 rpc,或其他 libco hook 了的非阻塞 IO
// `g_mutex` is released when lock goes out of scope
}协程 1 在持有线程锁的同时,yield 让出 CPU;同一个线程中的其他协程,获取得到 CPU,同样执行这一段代码,就会尝试去获取锁,但一直得不到锁,就阻塞了,从而整个线程都阻塞了。
Locks the [mutex] . If another thread has already locked the mutex, a call to lock will block execution until the lock is acquired.
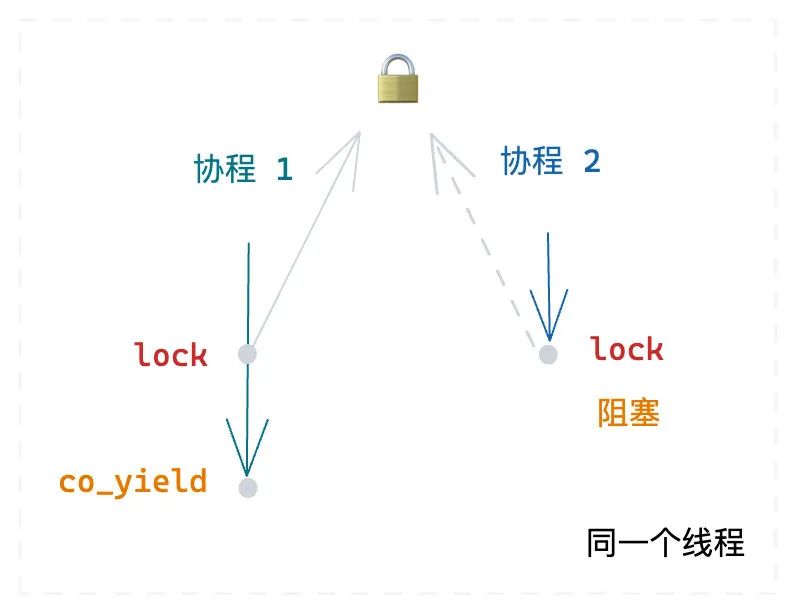
我们再来看一个隐式使用线程锁的例子,下面这段代码,一个经典的单例模式的实现:
// 示例 2: Meyers Singleton Pattern,隐式使用线程锁
class Singleton {
public:
static Singleton &GetInstance() {
static Singleton instance; // <--· here !!!
return instance;
}
private:
Singleton() { co_yield(); } // <--· here !!!
};
void hello() {
auto conf = Singleton::GetInstance();
// ... do sth with conf
}在进行单例构造时,使用 static 修饰,编译器为保证线程安全会为 static 的初始化添加线程锁 (默认开启,可添加编译选项 [-fno-threadsafe-statics] 关闭)。但业务开发在实现的时候,在对应的构造函数中调用 rpc yield 让出了 CPU;同样的,同一个线程中的其他协程也走到这一段代码,尝试获取单例,就出现了死锁。这样就与第一个例子中显示使用线程锁,所导致的问题,是一致的了。
使用 [cppinsights] 从编译器 (clang) 的角度看看代码,文档 [cxx-abi] ,[对应实现] 。
在 Rust 中提供了专门用于异步运行时的 mutex,再次尝试获取时,如果获取不到,就会直接 yield
https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=fd3b0f156a35dc9c64add06e8118b04e
可以很好的解决这里的问题,协程 1 持有了锁,主动让出 CPU,协程 2 尝试获取锁,肯定获取不到,就会主动 yield,协程 1 继续执行,执行完后,释放锁,协程 2 就可以获取得到锁,继续执行。
到这里第四部就结束了。
接下来,对今天的分享做一个总结。
总结
在今天的协程分享中,我尝试去回答了以下四个问题:
- Q1 (Why): 为什么需要协程?
- Q2 (What): 到底什么是协程?
- Q3 (How): 怎么实现协程 (库)?
- Q4 (Usage): 同时,列举了我们在使用协程时需要注意的一些问题?
主要的一个思想是,协程的概念其实很简单 -- 协程就是一个 “可以暂停和恢复执行” 的函数,其“全部精神就在于控制流的主动让出和恢复”。
在现在的高级语言中,实现协程思想的方法很多,这些实现间并无高下之分,所区别的仅仅是其适合的应用场景。
理解这一点,我们对于各种协程的分类,如对称/非对称协程、有栈与无栈协程,就能够更加明白其本质,而无需在实现细节上过于纠结。