Buddy 内存管理机制(下)
- 内存释放
- 内存分配
- gfp_mask
- node 候选策略
- zone 候选策略
- zone fallback 策略
- lowmem reserve 机制
- order fallback 策略
- migrate type 候选策略
- migrate fallback 策略
- reclaim watermark
- reclaim 方式
- alloc_pages()
内存释放
Buddy 系统中,相比较内存的分配,内存的释放过程更简单,我们先来解析这部分。
这里体现了 Buddy 的核心思想:在内存释放时判断其 buddy 兄弟 page 是不是 order 大小相等的 free page,如果是则合并成更高一阶 order。这样的目的是最大可能的减少内存碎片化。
内存释放最后都会落到 __free_pages() 函数:
void __free_pages(struct page *page, unsigned int order)
{
/* (1) 对page->_refcount减1后并判断是否为0
如果引用计数为0了,说明可以释放page了
*/
if (put_page_testzero(page))
free_the_page(page, order);
}
↓
static inline void free_the_page(struct page *page, unsigned int order)
{
/* (1) 单个 page 首先尝试释放到 pcp */
if (order == 0) /* Via pcp? */
free_unref_page(page);
/* (2) 大于 1 的 2^order 个 page,释放到 order free_area_ 当中 */
else
__free_pages_ok(page, order);
}
↓
static void __free_pages_ok(struct page *page, unsigned int order)
{
unsigned long flags;
int migratetype;
unsigned long pfn = page_to_pfn(page);
/* (2.1) page释放前的一些动作:
清理一些成员
做一些检查
执行一些回调函数
*/
if (!free_pages_prepare(page, order, true))
return;
/* (2.2) 获取到page所在pageblock的migrate type
当前page会被释放到对应order free_area的对应 migrate freelist链表当中
*/
migratetype = get_pfnblock_migratetype(page, pfn);
local_irq_save(flags);
__count_vm_events(PGFREE, 1 << order);
/* (2.3) 向zone中释放page */
free_one_page(page_zone(page), page, pfn, order, migratetype);
local_irq_restore(flags);
}
↓
free_one_page()
↓
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype)
{
unsigned long combined_pfn;
unsigned long uninitialized_var(buddy_pfn);
struct page *buddy;
unsigned int max_order;
max_order = min_t(unsigned int, MAX_ORDER, pageblock_order + 1);
VM_BUG_ON(!zone_is_initialized(zone));
VM_BUG_ON_PAGE(page->flags & PAGE_FLAGS_CHECK_AT_PREP, page);
VM_BUG_ON(migratetype == -1);
if (likely(!is_migrate_isolate(migratetype)))
__mod_zone_freepage_state(zone, 1 << order, migratetype);
VM_BUG_ON_PAGE(pfn & ((1 << order) - 1), page);
VM_BUG_ON_PAGE(bad_range(zone, page), page);
continue_merging:
/* (2.3.1) 尝试对释放的(2^order)长度的page进行逐级向上合并 */
while (order < max_order - 1) {
/* (2.3.1.1) 得到当前释放的(2^order)长度page对应的buddy伙伴page指针
计算伙伴buddy使用和(1<<order)进行异或:(0<<order)pfn对应的伙伴page为(1<<order)pfn,(1<<order)pfn对应的伙伴page为(0<<order)pfn
*/
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
if (!pfn_valid_within(buddy_pfn))
goto done_merging;
/* (2.3.1.2) 判断伙伴page的是否是buddy状态:
是否是free状态在buddy系统中(page->_mapcount == PAGE_BUDDY_MAPCOUNT_VALUE)
当前的free order和要释放的order相等(page->private == order)
*/
if (!page_is_buddy(page, buddy, order))
goto done_merging;
/*
* Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,
* merge with it and move up one order.
*/
if (page_is_guard(buddy)) {
clear_page_guard(zone, buddy, order, migratetype);
} else {
/* (2.3.1.3) 如果满足合并的条件,则准备开始合并
把伙伴page从原freelist中删除
*/
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
/* 清理page中保存的order信息:
page->_mapcount = -1
page->private = 0
*/
rmv_page_order(buddy);
}
/* (2.3.1.4) 组成了更高一级order的空闲内存 */
combined_pfn = buddy_pfn & pfn;
page = page + (combined_pfn - pfn);
pfn = combined_pfn;
order++;
}
if (max_order < MAX_ORDER) {
/* If we are here, it means order is >= pageblock_order.
* 如果在这里,意味着order >= pageblock_order。
* We want to prevent merge between freepages on isolate
* pageblock and normal pageblock. Without this, pageblock
* isolation could cause incorrect freepage or CMA accounting.
* 我们要防止隔离页面块和正常页面块上的空闲页面合并。 否则,页面块隔离可能导致不正确的空闲页面或CMA计数。
*
* We don't want to hit this code for the more frequent
* low-order merging.
* 我们不想命中此代码进行频繁的低阶合并。
*/
if (unlikely(has_isolate_pageblock(zone))) {
int buddy_mt;
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
buddy_mt = get_pageblock_migratetype(buddy);
if (migratetype != buddy_mt
&& (is_migrate_isolate(migratetype) ||
is_migrate_isolate(buddy_mt)))
goto done_merging;
}
max_order++;
goto continue_merging;
}
/* (2.3.2) 开始挂载合并成order的空闲内存 */
done_merging:
/* (2.3.2.1) page中保存order大小:
page->_mapcount = PAGE_BUDDY_MAPCOUNT_VALUE(-128)
page->private = order
*/
set_page_order(page, order);
/*
* If this is not the largest possible page, check if the buddy
* of the next-highest order is free. If it is, it's possible
* that pages are being freed that will coalesce soon. In case,
* that is happening, add the free page to the tail of the list
* so it's less likely to be used soon and more likely to be merged
* as a higher order page
* 如果这不是最大的页面,请检查倒数第二个order的伙伴是否空闲。 如果是这样,则可能是页面即将被释放,即将合并。 万一发生这种情况,请将空闲页面添加到列表的末尾,这样它就不太可能很快被使用,而更有可能被合并为高阶页面
*/
/* (2.3.2.2) 将空闲page加到对应order链表的尾部 */
if ((order < MAX_ORDER-2) && pfn_valid_within(buddy_pfn)) {
struct page *higher_page, *higher_buddy;
combined_pfn = buddy_pfn & pfn;
higher_page = page + (combined_pfn - pfn);
buddy_pfn = __find_buddy_pfn(combined_pfn, order + 1);
higher_buddy = higher_page + (buddy_pfn - combined_pfn);
if (pfn_valid_within(buddy_pfn) &&
page_is_buddy(higher_page, higher_buddy, order + 1)) {
list_add_tail(&page->lru,
&zone->free_area[order].free_list[migratetype]);
goto out;
}
}
/* (2.3.2.3) 将空闲page加到对应order链表的开始 */
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
out:
zone->free_area[order].nr_free++;
}PageBuddy()用来判断page是否在buddy系统中,还有很多类似的page操作函数都定义在page-flags.h当中:
linux-source-4.15.0\include\linux\page-flags.h:
#define PAGE_MAPCOUNT_OPS(uname, lname) \
static __always_inline int Page##uname(struct page *page) \
{ \
return atomic_read(&page->_mapcount) == \
PAGE_##lname##_MAPCOUNT_VALUE; \
} \
static __always_inline void __SetPage##uname(struct page *page) \
{ \
VM_BUG_ON_PAGE(atomic_read(&page->_mapcount) != -1, page); \
atomic_set(&page->_mapcount, PAGE_##lname##_MAPCOUNT_VALUE); \
} \
static __always_inline void __ClearPage##uname(struct page *page) \
{ \
VM_BUG_ON_PAGE(!Page##uname(page), page); \
atomic_set(&page->_mapcount, -1); \
}
/*
* PageBuddy() indicate that the page is free and in the buddy system
* (see mm/page_alloc.c).
*/
#define PAGE_BUDDY_MAPCOUNT_VALUE (-128)
PAGE_MAPCOUNT_OPS(Buddy, BUDDY)对于单个page,会首先释放到percpu缓存中:
start_kernel() → mm_init() → mem_init() → free_all_bootmem() free_low_memory_core_early() → __free_memory_core() → __free_pages_memory() → __free_pages_bootmem() → __free_pages() → free_the_page() → free_unref_page():
↓
void free_unref_page(struct page *page)
{
unsigned long flags;
unsigned long pfn = page_to_pfn(page);
/* (1) 一些初始化准备工作
page->index = migratetype;
*/
if (!free_unref_page_prepare(page, pfn))
return;
local_irq_save(flags);
/* (2) 释放page到pcp中 */
free_unref_page_commit(page, pfn);
local_irq_restore(flags);
}
↓
static void free_unref_page_commit(struct page *page, unsigned long pfn)
{
struct zone *zone = page_zone(page);
struct per_cpu_pages *pcp;
int migratetype;
/* (2.1) migratetype = page->index */
migratetype = get_pcppage_migratetype(page);
__count_vm_event(PGFREE);
/* (2.2) 对于某些migratetype的特殊处理 */
if (migratetype >= MIGRATE_PCPTYPES) {
/* (2.2.1) 对于isolate类型,free到全局的freelist中 */
if (unlikely(is_migrate_isolate(migratetype))) {
free_one_page(zone, page, pfn, 0, migratetype);
return;
}
migratetype = MIGRATE_MOVABLE;
}
/* (2.3) 获取到zone当前cpu pcp的链表头 */
pcp = &this_cpu_ptr(zone->pageset)->pcp;
/* (2.4) 将空闲的单page加入到pcp对应链表中 */
list_add(&page->lru, &pcp->lists[migratetype]);
pcp->count++;
/* (2.5) 如果pcp中的page数量过多(大于pcp->high),释放pcp->batch个page到全局free list当中去 */
if (pcp->count >= pcp->high) {
unsigned long batch = READ_ONCE(pcp->batch);
free_pcppages_bulk(zone, batch, pcp);
pcp->count -= batch;
}
}pcp->high 和 pcp->batch 的赋值过程:
start_kernel() → setup_per_cpu_pageset() → setup_zone_pageset() → zone_pageset_init() → pageset_set_high_and_batch():
|→
static int zone_batchsize(struct zone *zone)
{
/* batch 的大小 = (zone_size / (1024*4)) * (3/2) */
batch = zone->managed_pages / 1024;
if (batch * PAGE_SIZE > 512 * 1024)
batch = (512 * 1024) / PAGE_SIZE;
batch /= 4; /* We effectively *= 4 below */
if (batch < 1)
batch = 1;
batch = rounddown_pow_of_two(batch + batch/2) - 1;
return batch;
}
|→
static void pageset_set_batch(struct per_cpu_pageset *p, unsigned long batch)
{
/* high = 6 * batch */
pageset_update(&p->pcp, 6 * batch, max(1UL, 1 * batch));
}内存分配
相比较释放,内存分配的策略要复杂的多,要考虑的因素也多很多,让我们一一来解析。
gfp_mask
gfp_mask是GFP(Get Free Page)相关的一系列标志,控制了分配page的一系列行为。
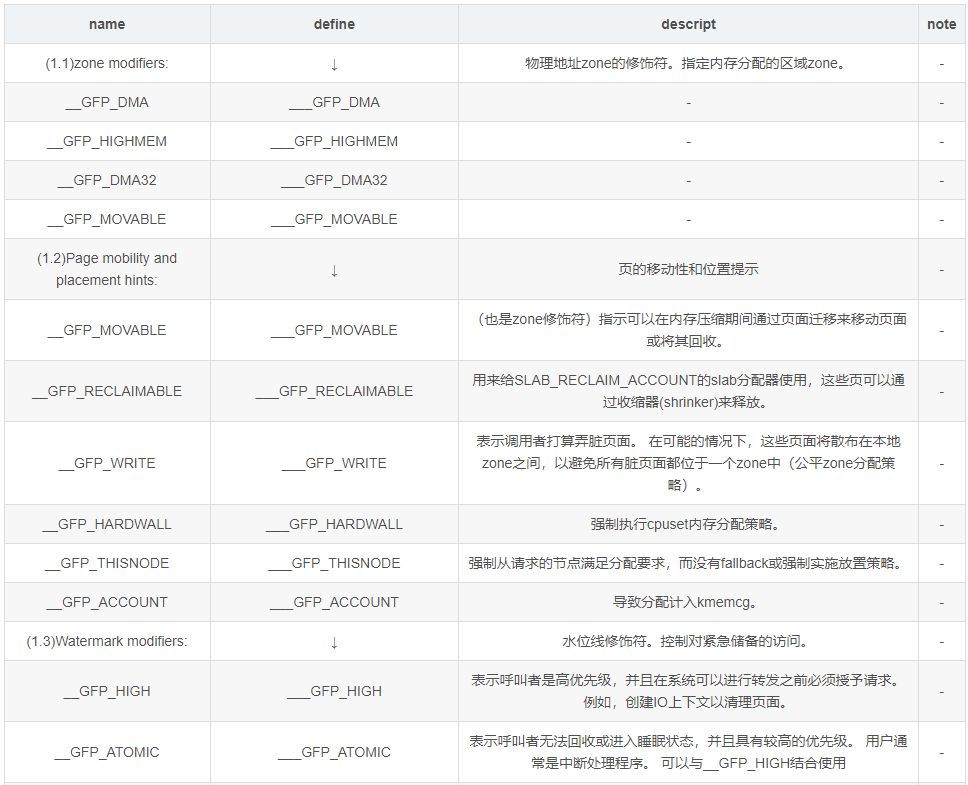
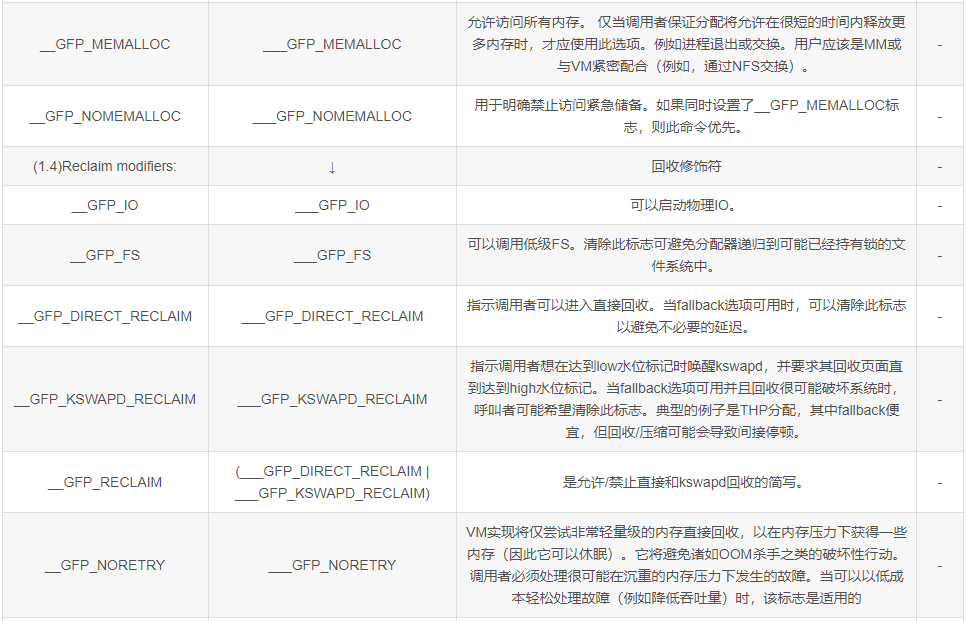
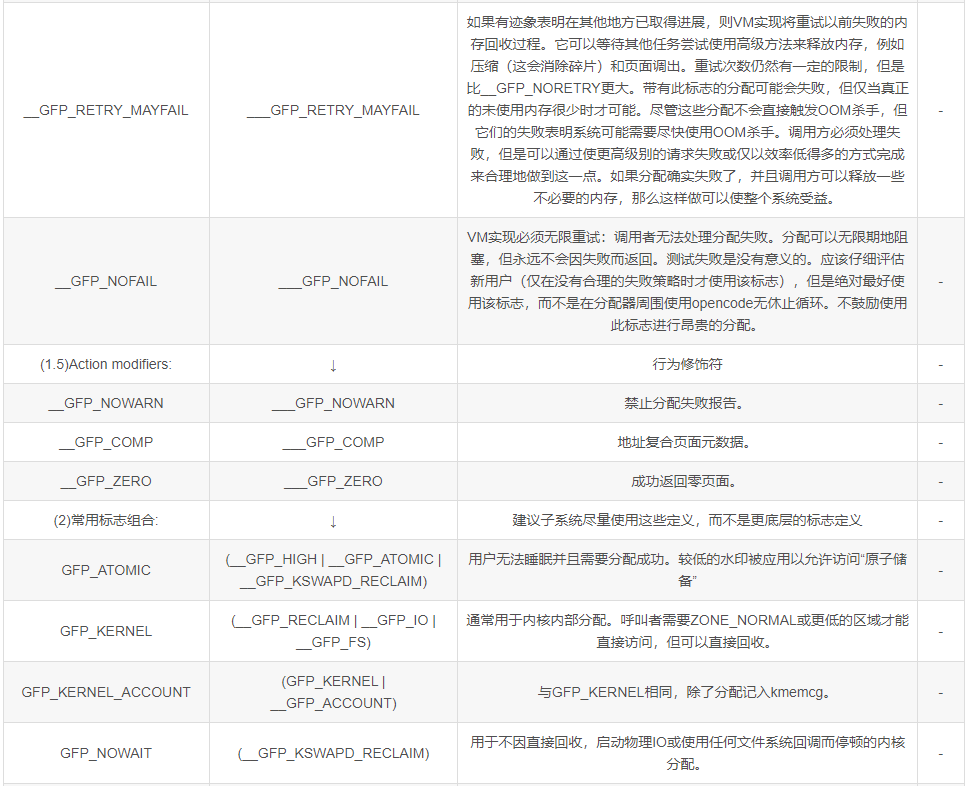
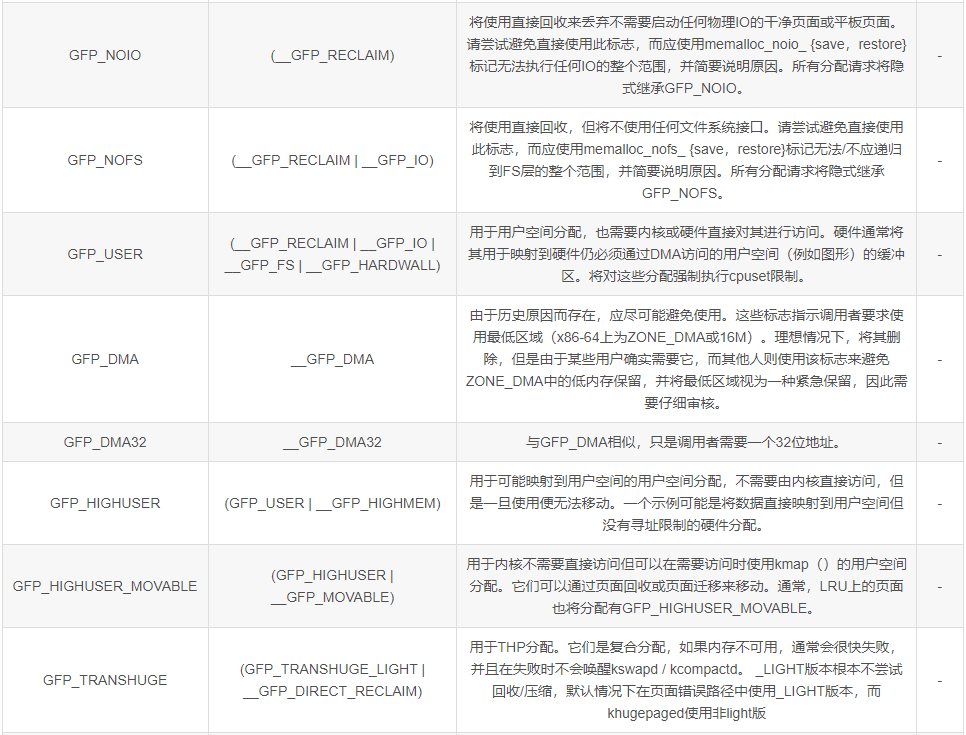

node 候选策略
在 NUMA 的情况下,会有多个 memory node 可供选择,系统会根据 policy 选择当前分配的 node。
alloc_pages() → alloc_pages_current():
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
/* (1.1) 使用默认NUMA策略 */
struct mempolicy *pol = &default_policy;
struct page *page;
/* (1.2) 获取当前进程的NUMA策略 */
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
/* (2) 从NUMA策略指定的首选node和备选node组上,进行内存页面的分配 */
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}zone 候选策略
Buddy 系统中对每一个 node 定义了多个类型的 zone :
enum zone_type {
ZONE_DMA,
ZONE_DMA32,
ZONE_NORMAL,
ZONE_HIGHMEM,
ZONE_MOVABLE,
ZONE_DEVICE,
__MAX_NR_ZONES
};gfp_mask 中也定义了一系列选择 zone 的flag:
/*
* Physical address zone modifiers (see linux/mmzone.h - low four bits)
*/
#define __GFP_DMA ((__force gfp_t)___GFP_DMA)
#define __GFP_HIGHMEM ((__force gfp_t)___GFP_HIGHMEM)
#define __GFP_DMA32 ((__force gfp_t)___GFP_DMA32)
#define __GFP_MOVABLE ((__force gfp_t)___GFP_MOVABLE) /* ZONE_MOVABLE allowed */
#define GFP_ZONEMASK (__GFP_DMA|__GFP_HIGHMEM|__GFP_DMA32|__GFP_MOVABLE)怎么样根据 gfp_mask 中的 zone modifiers 来选择分配锁使用的 zone 呢?系统设计了一套算法来进行转换:
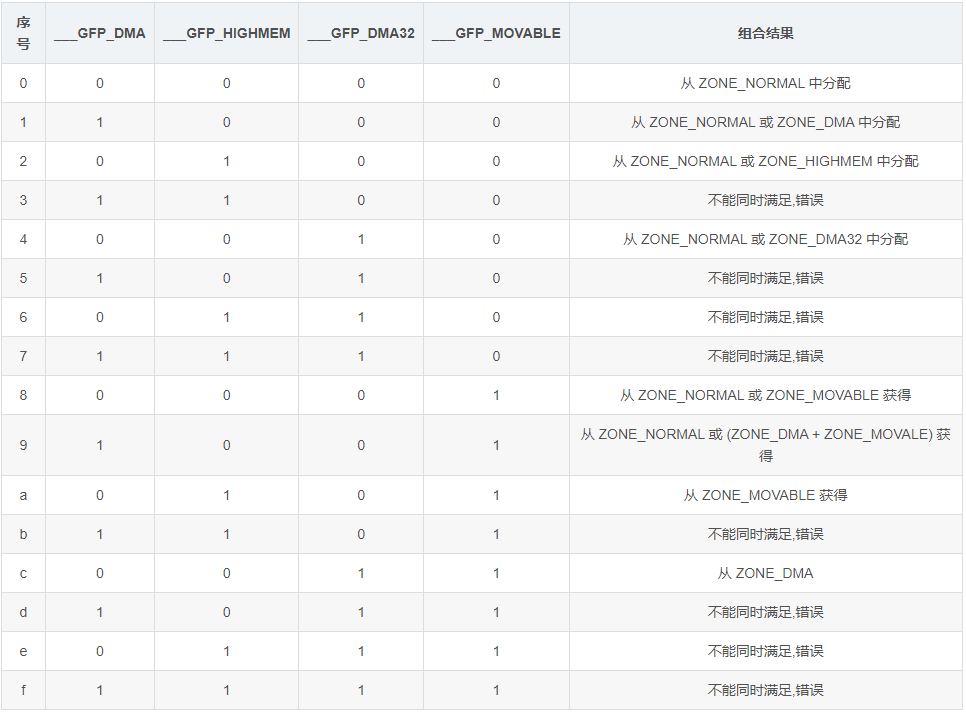
alloc_pages() → alloc_pages_current() → __alloc_pages_nodemask() → prepare_alloc_pages() → gfp_zone():
static inline enum zone_type gfp_zone(gfp_t flags)
{
enum zone_type z;
/* (1) gfp 标志中低4位为 zone modifiers */
int bit = (__force int) (flags & GFP_ZONEMASK);
/* (2) 查表得到最后的候选zone
内核规定 ___GFP_DMA,___GFP_HIGHMEM 和 ___GFP_DMA32 其两个或全部不能同时存在于 gfp 标志中
*/
z = (GFP_ZONE_TABLE >> (bit * GFP_ZONES_SHIFT)) &
((1 << GFP_ZONES_SHIFT) - 1);
VM_BUG_ON((GFP_ZONE_BAD >> bit) & 1);
return z;
}
#define GFP_ZONE_TABLE ( \
(ZONE_NORMAL << 0 * GFP_ZONES_SHIFT) \
| (OPT_ZONE_DMA << ___GFP_DMA * GFP_ZONES_SHIFT) \
| (OPT_ZONE_HIGHMEM << ___GFP_HIGHMEM * GFP_ZONES_SHIFT) \
| (OPT_ZONE_DMA32 << ___GFP_DMA32 * GFP_ZONES_SHIFT) \
| (ZONE_NORMAL << ___GFP_MOVABLE * GFP_ZONES_SHIFT) \
| (OPT_ZONE_DMA << (___GFP_MOVABLE | ___GFP_DMA) * GFP_ZONES_SHIFT) \
| (ZONE_MOVABLE << (___GFP_MOVABLE | ___GFP_HIGHMEM) * GFP_ZONES_SHIFT)\
| (OPT_ZONE_DMA32 << (___GFP_MOVABLE | ___GFP_DMA32) * GFP_ZONES_SHIFT)\
)
#define GFP_ZONE_BAD ( \
1 << (___GFP_DMA | ___GFP_HIGHMEM) \
| 1 << (___GFP_DMA | ___GFP_DMA32) \
| 1 << (___GFP_DMA32 | ___GFP_HIGHMEM) \
| 1 << (___GFP_DMA | ___GFP_DMA32 | ___GFP_HIGHMEM) \
| 1 << (___GFP_MOVABLE | ___GFP_HIGHMEM | ___GFP_DMA) \
| 1 << (___GFP_MOVABLE | ___GFP_DMA32 | ___GFP_DMA) \
| 1 << (___GFP_MOVABLE | ___GFP_DMA32 | ___GFP_HIGHMEM) \
| 1 << (___GFP_MOVABLE | ___GFP_DMA32 | ___GFP_DMA | ___GFP_HIGHMEM) \
)zone fallback 策略
通过上述的候选策略,我们选定了内存分配的 node 和 zone,然后开始分配。如果分配失败,我们并不会马上启动内存回收,而是通过 fallback 机制尝试从其他低级的 zone 中看看能不能借用一些内存。
fallback 的借用,只能从高级到低级的借用,而不能从低级到高级的借用。比如:原本想分配 Normal zone 的内存,失败的情况下可以尝试从 DMA32 zone 中分配内存,因为能用 normal zone 地址范围的内存肯定也可以用 DMA32 zone 地址范围的内存。但是反过来就不行,原本需要 DMA32 zone 地址范围的内存,你给他一个 normal zone 的内存,地址超过了4G,可能就超过了 DMA 设备的寻址能力。
系统还定义了一个 __GFP_THISNODE 标志,用来限制 fallback 时只能在本 node 上寻找合适的低级 zone。否则会在所有 node 上寻找合适的低级 zone。
该算法的具体实现如下:
- 1、每个 node 定义了 fallback 时用到的候选 zone 链表:
pgdat->node_zonelists[ZONELIST_FALLBACK] // 跨 node FALLBACK机制生效,用来链接所有node的所有zone
pgdat->node_zonelists[ZONELIST_NOFALLBACK] // 如果gfp_mask设置了__GFP_THISNODE标志,跨 node FALLBACK机制失效,用来链接本node的所有zone系统启动时初始化这些链表:
start_kernel() → build_all_zonelists() → __build_all_zonelists() → build_zonelists() → build_zonelists_in_node_order()/build_thisnode_zonelists() → build_zonerefs_node():
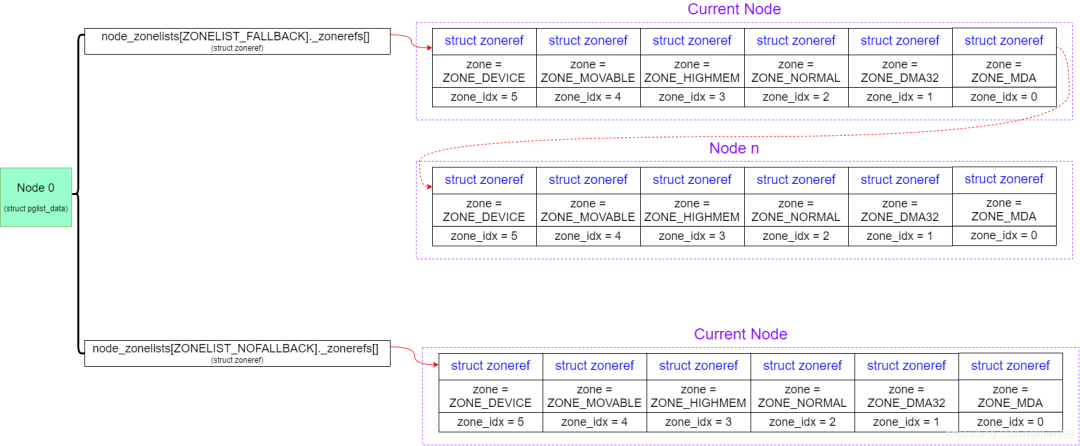
- 2、内存分配时确定使用的 fallback 链表:
alloc_pages() → alloc_pages_current() → __alloc_pages_nodemask() → prepare_alloc_pages() → node_zonelist():
static inline struct zonelist *node_zonelist(int nid, gfp_t flags)
{
/* (1) 根据fallback机制是否使能,来选择候选zone链表 */
return NODE_DATA(nid)->node_zonelists + gfp_zonelist(flags);
}
static inline int gfp_zonelist(gfp_t flags)
{
#ifdef CONFIG_NUMA
/* (1.1) 如果gfp_mask指定了__GFP_THISNODE,则跨 node fallback机制失效 */
if (unlikely(flags & __GFP_THISNODE))
return ZONELIST_NOFALLBACK;
#endif
/* (1.2) 否则,跨 node fallback机制生效 */
return ZONELIST_FALLBACK;
}
alloc_pages() → alloc_pages_current() → __alloc_pages_nodemask() → finalise_ac():
static inline void finalise_ac(gfp_t gfp_mask,
unsigned int order, struct alloc_context *ac)
{
/* Dirty zone balancing only done in the fast path */
ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE);
/* (2) 从fallback list中选取最佳候选zone,即本node的符合zone type条件的最高zone */
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}- 3、从原有zone分配失败时,尝试从 fallback zone 中分配内存:
alloc_pages() → alloc_pages_current() → __alloc_pages_nodemask() → get_page_from_freelist():
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z = ac->preferred_zoneref;
struct zone *zone;
/* (1) 如果分配失败,遍历 fallback list 中的 zone,逐个尝试分配 */
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
}
}lowmem reserve 机制
承接上述的 fallback 机制,高等级的 zone 可以借用低等级 zone 的内存。但是从理论上说,低等级的内存更加的宝贵因为它的空间更小,如果被高等级的侵占完了,那么用户需要低层级内存的时候就会分配失败。
为了解决这个问题,系统给每个 zone 能够给其他高等级 zone 借用的内存设置了一个预留值,可以借用内存但是本zone保留的内存不能小于这个值。
我们可以通过命令来查看每个 zone 的 lowmem reserve 大小设置,protection 字段描述了本zone给其他zone借用时必须保留的内存:
pwl@ubuntu:~$ cat /proc/zoneinfo
Node 0, zone DMA
pages free 3968
min 67
low 83
high 99
spanned 4095
present 3997
managed 3976
// 本 zone 为 DMA
// 给 DMA zone 借用时必须保留 0 pages
// 给 DMA32 zone 借用时必须保留 2934 pages
// 给 Normal/Movable/Device zone 借用时必须保留 3859 pages
protection: (0, 2934, 3859, 3859, 3859)
Node 0, zone DMA32
pages free 418978
min 12793
low 15991
high 19189
spanned 1044480
present 782288
managed 759701
// 本 zone 为 DMA32
// 给 DMA/DMA32 zone 借用时必须保留 0 pages
// 给 Normal/Movable/Device zone 借用时必须保留 925 pages
protection: (0, 0, 925, 925, 925)
nr_free_pages 418978
Node 0, zone Normal
pages free 4999
min 4034
low 5042
high 6050
spanned 262144
present 262144
managed 236890
// 本 zone 为 Normal
// 因为 Movable/Device zone 大小为0,所以给所有 zone 借用时必须保留 0 pages
protection: (0, 0, 0, 0, 0)
Node 0, zone Movable
pages free 0
min 0
low 0
high 0
spanned 0
present 0
managed 0
protection: (0, 0, 0, 0, 0)
Node 0, zone Device
pages free 0
min 0
low 0
high 0
spanned 0
present 0
managed 0
protection: (0, 0, 0, 0, 0) 可以通过lowmem_reserve_ratio来调节这个值的大小:
pwl@ubuntu:~$ cat /proc/sys/vm/lowmem_reserve_ratio
256 256 32 0 0order fallback 策略
Buddy 系统中对每一个 zone 又细分了多个 order 的 free_area:
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
#else
#define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER
#endif如果在对应 order 的 free_area 中找不多 free 内存的话,会逐个往高级别 order free_area 中查找,直至 max_order。
对高级别 order 的 freelist ,会被分割成多个低级别 order 的 freelist。
migrate type 候选策略
Buddy 系统中对每一个 zone 中的每一个 order free_area 又细分了多个 migrate type :
enum migratetype {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
MIGRATE_CMA,
MIGRATE_ISOLATE, /* can't allocate from here */
MIGRATE_TYPES
};gfp_mask 中也定义了一系列选择 migrate type 的flag:
#define __GFP_MOVABLE ((__force gfp_t)___GFP_MOVABLE) /* ZONE_MOVABLE allowed */
#define __GFP_RECLAIMABLE ((__force gfp_t)___GFP_RECLAIMABLE)
#define GFP_MOVABLE_MASK (__GFP_RECLAIMABLE|__GFP_MOVABLE)根据 gfp_mask 转换成 migrate type 的代码如下:
alloc_pages() → alloc_pages_current() → __alloc_pages_nodemask() → prepare_alloc_pages() → gfpflags_to_migratetype():
static inline int gfpflags_to_migratetype(const gfp_t gfp_flags)
{
VM_WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
BUILD_BUG_ON((1UL << GFP_MOVABLE_SHIFT) != ___GFP_MOVABLE);
BUILD_BUG_ON((___GFP_MOVABLE >> GFP_MOVABLE_SHIFT) != MIGRATE_MOVABLE);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
/* (1) 转换的结果仅为3种类型:MIGRATE_UNMOVABLE/MIGRATE_MOVABLE/MIGRATE_RECLAIMABLE */
return (gfp_flags & GFP_MOVABLE_MASK) >> GFP_MOVABLE_SHIFT;
}migrate fallback 策略
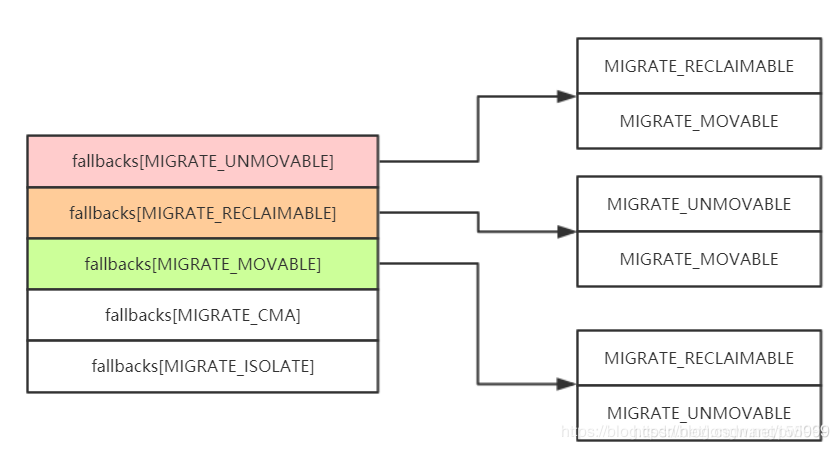
在指定 migrate type 的 order 和大于 order 的 free list 分配失败时,可以从同一 zone 的其他 migrate type freelist 中偷取内存。
static int fallbacks[MIGRATE_TYPES][4] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
#ifdef CONFIG_CMA
[MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */
#endif
#ifdef CONFIG_MEMORY_ISOLATION
[MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */
#endif
};
具体的代码如下:
alloc_pages() → alloc_pages_current() → __alloc_pages_nodemask() → get_page_from_freelist() → rmqueue() → __rmqueue() → __rmqueue_fallback():
reclaim watermark
分配时如果 freelist 中现有的内存不能满足需求,则会启动内充回收。系统对每个 zone 定义了三种内存水位 high/low/min,针对不同的水位采取不同的回收策略:
pwl@ubuntu:~$ cat /proc/zoneinfo
Node 0, zone DMA
pages free 3968
min 67
low 83
high 99
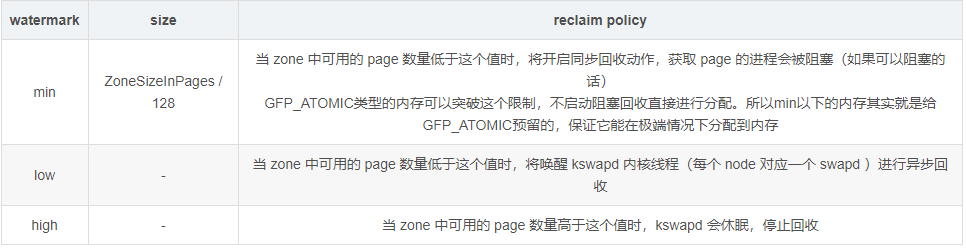
reclaim 方式
系统设计了几种回收内存的手段:
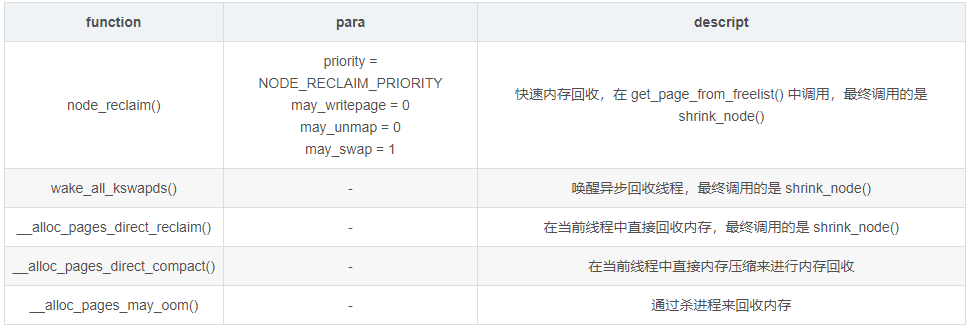
alloc_pages()
Buddy 内存分配的核心代码实现。
alloc_pages() → alloc_pages_current() → __alloc_pages_nodemask():
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
/* (1.1) 默认的允许水位为low */
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };
/*
* There are several places where we assume that the order value is sane
* so bail out early if the request is out of bound.
*/
/* (1.2) order长度的合法性判断 */
if (unlikely(order >= MAX_ORDER)) {
WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN));
return NULL;
}
/* (1.3) gfp_mask的过滤 */
gfp_mask &= gfp_allowed_mask;
alloc_mask = gfp_mask;
/* (1.4) 根据gfp_mask,决定的high_zoneidx、候选zone list、migrate type */
if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags))
return NULL;
/* (1.5) 挑选第一个合适的zone */
finalise_ac(gfp_mask, order, &ac);
/* First allocation attempt */
/* (2) 第1次分配:使用low水位尝试直接从free list分配page */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}.
*/
/* (3.1) 如果使用 memalloc_no{fs,io}_{save,restore} 设置了 NOFS和NOIO
从 current->flags 解析出相应的值,用来清除 gfp_mask 中相应的 __GFP_FS 和 __GFP_IO 标志
*/
alloc_mask = current_gfp_context(gfp_mask);
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
/* (3.2) 恢复原有的nodemask */
if (unlikely(ac.nodemask != nodemask))
ac.nodemask = nodemask;
/* (4) 慢速分配路径:使用min水位,以及各种手段进行内存回收后,再尝试分配内存 */
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
out:
if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&
unlikely(memcg_kmem_charge(page, gfp_mask, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
return page;
}
|→
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order,
int preferred_nid, nodemask_t *nodemask,
struct alloc_context *ac, gfp_t *alloc_mask,
unsigned int *alloc_flags)
{
/* (1.4.1) 根据gfp_mask,获取到可能的最高优先级的zone */
ac->high_zoneidx = gfp_zone(gfp_mask);
/* (1.4.2) 根据gfp_mask,获取到可能候选node的所有zone链表 */
ac->zonelist = node_zonelist(preferred_nid, gfp_mask);
ac->nodemask = nodemask;
/* (1.4.3) 根据gfp_mask,获取到migrate type
MIGRATE_UNMOVABLE/MIGRATE_MOVABLE/MIGRATE_RECLAIMABLE
*/
ac->migratetype = gfpflags_to_migratetype(gfp_mask);
/* (1.4.4) 如果cpuset cgroup使能,设置相应标志位 */
if (cpusets_enabled()) {
*alloc_mask |= __GFP_HARDWALL;
if (!ac->nodemask)
ac->nodemask = &cpuset_current_mems_allowed;
else
*alloc_flags |= ALLOC_CPUSET;
}
/* (1.4.5) 如果指定了__GFP_FS,则尝试获取fs锁 */
fs_reclaim_acquire(gfp_mask);
fs_reclaim_release(gfp_mask);
/* (1.4.6) 如果指定了__GFP_DIRECT_RECLAIM,判断当前是否是非原子上下文可以睡眠 */
might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM);
if (should_fail_alloc_page(gfp_mask, order))
return false;
/* (1.4.7) 让MIGRATE_MOVABLE可以使用MIGRATE_CMA区域 */
if (IS_ENABLED(CONFIG_CMA) && ac->migratetype == MIGRATE_MOVABLE)
*alloc_flags |= ALLOC_CMA;
return true;
}get_page_from_freelist()
第一次的快速内存分配,和后续的慢速内存分配,最后都是调用 get_page_from_freelist() 从freelist中获取内存。
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z = ac->preferred_zoneref;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
/* (2.5.1) 轮询 fallback zonelist链表,在符合条件(idx<=high_zoneidx)的zone中尝试分配内存 */
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
/* (2.5.2) 如果__GFP_WRITE指示了分配页的用途是dirty,平均分布脏页
查询node上分配的脏页是否超过限制,超过则换node
*/
if (ac->spread_dirty_pages) {
if (last_pgdat_dirty_limit == zone->zone_pgdat)
continue;
if (!node_dirty_ok(zone->zone_pgdat)) {
last_pgdat_dirty_limit = zone->zone_pgdat;
continue;
}
}
/* (2.5.3) 获取当前分配能超越的水位线 */
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
/* (2.5.4) 判断当前zone中的free page是否满足条件:
1、total free page >= (2^order) + watermark + lowmem_reserve
2、是否有符合要求的长度为(2^order)的连续内存
*/
if (!zone_watermark_fast(zone, order, mark,
ac_classzone_idx(ac), alloc_flags)) {
int ret;
/* (2.5.5) 如果没有足够的free内存,则进行下列的判断 */
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
/* (2.5.6) 如果可以忽略水位线,则直接进行分配尝试 */
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
if (node_reclaim_mode == 0 ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
/* (2.5.7) 快速内存回收尝试回收(2^order)个page
快速回收不能进行unmap,writeback操作,回收priority为4,即最多尝试调用shrink_node进行回收的次数为priority值
在__node_reclaim()中使用以下 scan_control 参数来调用shrink_node(),
struct scan_control sc = {
.nr_to_reclaim = max(nr_pages, SWAP_CLUSTER_MAX),
.gfp_mask = current_gfp_context(gfp_mask),
.order = order,
.priority = NODE_RECLAIM_PRIORITY,
.may_writepage = !!(node_reclaim_mode & RECLAIM_WRITE), // 默认为0
.may_unmap = !!(node_reclaim_mode & RECLAIM_UNMAP), // 默认为0
.may_swap = 1,
.reclaim_idx = gfp_zone(gfp_mask),
};
*/
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
/* (2.5.8) 如果回收成功,重新判断空闲内存是否已经足够 */
if (zone_watermark_ok(zone, order, mark,
ac_classzone_idx(ac), alloc_flags))
goto try_this_zone;
continue;
}
}
try_this_zone:
/* (2.5.9) 满足条件,尝试实际的从free list中摘取(2^order)个page */
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
/* (2.5.10) 分配到内存后,对 struct page 的一些处理 */
prep_new_page(page, order, gfp_mask, alloc_flags);
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
}
}
return NULL;
}
||→
static inline bool zone_watermark_fast(struct zone *z, unsigned int order,
unsigned long mark, int classzone_idx, unsigned int alloc_flags)
{
/* (2.5.4.1) 获取当前zone中free page的数量 */
long free_pages = zone_page_state(z, NR_FREE_PAGES);
long cma_pages = 0;
#ifdef CONFIG_CMA
/* If allocation can't use CMA areas don't use free CMA pages */
if (!(alloc_flags & ALLOC_CMA))
cma_pages = zone_page_state(z, NR_FREE_CMA_PAGES);
#endif
/* (2.5.4.2) 对order=0的长度,进行快速检测free内存是否够用 */
if (!order && (free_pages - cma_pages) > mark + z->lowmem_reserve[classzone_idx])
return true;
/* (2.5.4.3) 慢速检测free内存是否够用 */
return __zone_watermark_ok(z, order, mark, classzone_idx, alloc_flags,
free_pages);
}
|||→
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int classzone_idx, unsigned int alloc_flags,
long free_pages)
{
long min = mark;
int o;
const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));
/* free_pages may go negative - that's OK */
/* (2.5.4.3.1) 首先用free page总数减去需要的order长度,判断剩下的长度是不是还超过水位线 */
free_pages -= (1 << order) - 1;
/* (2.5.4.3.2) 如果是优先级高,水位线可以减半 */
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
/*
* If the caller does not have rights to ALLOC_HARDER then subtract
* the high-atomic reserves. This will over-estimate the size of the
* atomic reserve but it avoids a search.
*/
/* (2.5.4.3.3) 非harder类的分配,free内存还需预留nr_reserved_highatomic的内存 */
if (likely(!alloc_harder)) {
free_pages -= z->nr_reserved_highatomic;
/* (2.5.4.3.4) harder类的分配,非常紧急了,水位线还可以继续减半缩小 */
} else {
/*
* OOM victims can try even harder than normal ALLOC_HARDER
* users on the grounds that it's definitely going to be in
* the exit path shortly and free memory. Any allocation it
* makes during the free path will be small and short-lived.
*/
if (alloc_flags & ALLOC_OOM)
min -= min / 2;
else
min -= min / 4;
}
#ifdef CONFIG_CMA
/* If allocation can't use CMA areas don't use free CMA pages */
/* (2.5.4.3.5) 非CMA的分配,free内存还需预留CMA内存 */
if (!(alloc_flags & ALLOC_CMA))
free_pages -= zone_page_state(z, NR_FREE_CMA_PAGES);
#endif
/*
* Check watermarks for an order-0 allocation request. If these
* are not met, then a high-order request also cannot go ahead
* even if a suitable page happened to be free.
*/
/* (2.5.4.3.6) free内存还要预留(水位内存+lowmem_reserve[classzone_idx])
如果减去上述所有的预留内存内存后,还大于请求的order长度,说明当前zone中的free内存总长度满足请求分配的order
但是有没有符合要求的长度为(2^order)的连续内存,还要进一步查找判断
*/
if (free_pages <= min + z->lowmem_reserve[classzone_idx])
return false;
/* If this is an order-0 request then the watermark is fine */
/* (2.5.4.3.7) 如果order为0,不用进一步判断了,总长度满足,肯定能找到合适长度的page */
if (!order)
return true;
/* For a high-order request, check at least one suitable page is free */
/* (2.5.4.3.8) 逐个查询当前zone中大于请求order的链表 */
for (o = order; o < MAX_ORDER; o++) {
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
/* (2.5.4.3.9) 逐个查询当前order中的每个migrate type链表,如果不为空则返回成功 */
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!list_empty(&area->free_list[mt]))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!list_empty(&area->free_list[MIGRATE_CMA])) {
return true;
}
#endif
if (alloc_harder &&
!list_empty(&area->free_list[MIGRATE_HIGHATOMIC]))
return true;
}
return false;
}rmqueue()
找到合适有足够 free 内存的zone以后,rmqueue()负责从 freelist 中摘取 page。
rmqueue() → __rmqueue():
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype)
{
struct page *page;
retry:
/* (1) 从原始指定的 migrate freeist 中分配内存 */
page = __rmqueue_smallest(zone, order, migratetype);
if (unlikely(!page)) {
if (migratetype == MIGRATE_MOVABLE)
page = __rmqueue_cma_fallback(zone, order);
/* (2) 如果上一步分配失败,尝试从其他 migrate list 中偷取内存来分配 */
if (!page && __rmqueue_fallback(zone, order, migratetype))
goto retry;
}
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}
↓
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
/* (1.1) 逐个查询 >= order 的 freaa_area 中 migratetype 的freelist,看看是否有free内存 */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)
continue;
/* (1.1.1) 从 freelist 中摘取内存 */
list_del(&page->lru);
/* 清理page中保存的order信息:
page->_mapcount = -1
page->private = 0
*/
rmv_page_order(page);
area->nr_free--;
/* (1.1.2) 把剩余内存重新挂载到低阶 order 的freelist中 */
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}__alloc_pages_slowpath()
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;
struct page *page = NULL;
unsigned int alloc_flags;
unsigned long did_some_progress;
enum compact_priority compact_priority;
enum compact_result compact_result;
int compaction_retries;
int no_progress_loops;
unsigned int cpuset_mems_cookie;
int reserve_flags;
/*
* We also sanity check to catch abuse of atomic reserves being used by
* callers that are not in atomic context.
*/
if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==
(__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)))
gfp_mask &= ~__GFP_ATOMIC;
retry_cpuset:
compaction_retries = 0;
no_progress_loops = 0;
compact_priority = DEF_COMPACT_PRIORITY;
cpuset_mems_cookie = read_mems_allowed_begin();
/*
* The fast path uses conservative alloc_flags to succeed only until
* kswapd needs to be woken up, and to avoid the cost of setting up
* alloc_flags precisely. So we do that now.
*/
/* (1) 设置各种标志:
ALLOC_WMARK_MIN,水位降低到 min
ALLOC_HARDER,如果是 atomic 或者 rt_task,进一步降低水位
*/
alloc_flags = gfp_to_alloc_flags(gfp_mask);
/*
* We need to recalculate the starting point for the zonelist iterator
* because we might have used different nodemask in the fast path, or
* there was a cpuset modification and we are retrying - otherwise we
* could end up iterating over non-eligible zones endlessly.
*/
/* (2) 重新安排 fallback zone list */
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
if (!ac->preferred_zoneref->zone)
goto nopage;
/* (3) 进入慢速路径,说明在 low 水位下已经分配失败了,
所以先唤醒 kswapd 异步回收线程
*/
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
wake_all_kswapds(order, ac);
/*
* The adjusted alloc_flags might result in immediate success, so try
* that first
*/
/* (4) 第2次分配:使用min水位尝试直接从free list分配page */
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/*
* For costly allocations, try direct compaction first, as it's likely
* that we have enough base pages and don't need to reclaim. For non-
* movable high-order allocations, do that as well, as compaction will
* try prevent permanent fragmentation by migrating from blocks of the
* same migratetype.
* 对于昂贵的分配,首先尝试直接压缩,因为我们可能有足够的基本页,不需要回收。对于不可移动的高阶分配,也要这样做,因为压缩将尝试通过从相同migratetype的块迁移来防止永久的碎片化。
* Don't try this for allocations that are allowed to ignore
* watermarks, as the ALLOC_NO_WATERMARKS attempt didn't yet happen.
* 不要尝试这个分配而允许忽略水位,因为alloc_no_watermark尝试还没有发生。
*/
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
/* (5) 第3次分配:内存压缩compact后,尝试分配 get_page_from_freelist() */
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
/*
* Checks for costly allocations with __GFP_NORETRY, which
* includes THP page fault allocations
*/
if (costly_order && (gfp_mask & __GFP_NORETRY)) {
/*
* If compaction is deferred for high-order allocations,
* it is because sync compaction recently failed. If
* this is the case and the caller requested a THP
* allocation, we do not want to heavily disrupt the
* system, so we fail the allocation instead of entering
* direct reclaim.
*/
if (compact_result == COMPACT_DEFERRED)
goto nopage;
/*
* Looks like reclaim/compaction is worth trying, but
* sync compaction could be very expensive, so keep
* using async compaction.
*/
compact_priority = INIT_COMPACT_PRIORITY;
}
}
retry:
/* Ensure kswapd doesn't accidentally go to sleep as long as we loop */
/* (6) 再一次唤醒 kswapd 异步回收线程,可能ac参数变得更严苛了 */
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
wake_all_kswapds(order, ac);
/* (7) 设置各种标志:
ALLOC_NO_WATERMARKS,进一步降低水位,直接忽略水位
*/
reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);
if (reserve_flags)
alloc_flags = reserve_flags;
/*
* Reset the zonelist iterators if memory policies can be ignored.
* These allocations are high priority and system rather than user
* orientated.
*/
if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) {
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}
/* Attempt with potentially adjusted zonelist and alloc_flags */
/* (8) 第4次分配:使用no水位尝试直接从free list分配page */
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/* Caller is not willing to reclaim, we can't balance anything */
/* (9) 如果当前不支持直接回收,则退出,等待 kswapd 异步线程的回收 */
if (!can_direct_reclaim)
goto nopage;
/* Avoid recursion of direct reclaim */
/* (10) 避免递归回收 */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* Try direct reclaim and then allocating */
/* (11) 第5次分配:直接启动内存回收后,并尝试page get_page_from_freelist() */
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* Try direct compaction and then allocating */
/* (12) 第6次分配:直接启动内存压缩后,并尝试page get_page_from_freelist() */
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
/* Do not loop if specifically requested */
/* (13) 如果还是分配失败,且不支持重试,出错返回 */
if (gfp_mask & __GFP_NORETRY)
goto nopage;
/*
* Do not retry costly high order allocations unless they are
* __GFP_RETRY_MAYFAIL
*/
if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))
goto nopage;
/* (14) 检查重试内存回收是否有意义 */
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
/*
* It doesn't make any sense to retry for the compaction if the order-0
* reclaim is not able to make any progress because the current
* implementation of the compaction depends on the sufficient amount
* of free memory (see __compaction_suitable)
*/
/* (15) 检查重试内存压缩是否有意义 */
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
/* Deal with possible cpuset update races before we start OOM killing */
/* (16) 在启动 OOM kiling 之前,是否有可能更新 cpuset 来进行重试 */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/* Reclaim has failed us, start killing things */
/* (17) 第7次分配:所有的内存回收尝试都已经失败,祭出最后的大招:通过杀进程来释放内存 */
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
/* Avoid allocations with no watermarks from looping endlessly */
/* (18) 避免无止境循环的无水位分配 */
if (tsk_is_oom_victim(current) &&
(alloc_flags == ALLOC_OOM ||
(gfp_mask & __GFP_NOMEMALLOC)))
goto nopage;
/* Retry as long as the OOM killer is making progress */
/* (19) 在OOM killing取得进展时重试 */
if (did_some_progress) {
no_progress_loops = 0;
goto retry;
}
nopage:
/* Deal with possible cpuset update races before we fail */
/* (20) 在我们失败之前处理可能的cpuset更新 */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/*
* Make sure that __GFP_NOFAIL request doesn't leak out and make sure
* we always retry
*/
/* (21) 如果指定了 __GFP_NOFAIL,只能不停的进行重试 */
if (gfp_mask & __GFP_NOFAIL) {
/*
* All existing users of the __GFP_NOFAIL are blockable, so warn
* of any new users that actually require GFP_NOWAIT
*/
if (WARN_ON_ONCE(!can_direct_reclaim))
goto fail;
WARN_ON_ONCE(current->flags & PF_MEMALLOC);
WARN_ON_ONCE(order > PAGE_ALLOC_COSTLY_ORDER);
page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_HARDER, ac);
if (page)
goto got_pg;
cond_resched();
goto retry;
}
fail:
/* (22) 构造分配失败的告警信息 */
warn_alloc(gfp_mask, ac->nodemask,
"page allocation failure: order:%u", order);
got_pg:
return page;
}end