图解原理|Linux I/O 神器之 io_uring
io_uring 是 Linux 于 2019 年加入到内核的一种新型异步 I/O 模型,io_uring 主要为了解决 原生AIO(Native AIO) 存在的一些不足之处。下面介绍一下原生 AIO 的不足之处:
- 系统调用开销大:提交 I/O 操作和获取 I/O 操作的结果都需要通过系统调用完成,而触发系统调用时,需求进行上下文切换。在高 IOPS(Input/Output Per Second)的情况下,进行上下文切换也会消耗大量的CPU时间。
- 仅支持 Direct I/O(直接I/O):在使用原生 AIO 的时候,只能指定
O_DIRECT标识位(直接 I/O),不能借助文件系统的页缓存(page cache)来缓存当前的 I/O 请求。 - 对数据有大小对齐限制:所有写操作的数据大小必须是文件系统块大小(一般为4KB)的倍数,而且要与内存页大小对齐。
- 数据拷贝开销大:每个 I/O 提交需要拷贝 64+8 字节,每个 I/O 完成结果需要拷贝 32 字节,总共 104 字节的拷贝。这个拷贝开销是否可以承受,和单次 I/O 大小有关:如果需要发送的 I/O 本身就很大,相较之下,这点消耗可以忽略。而在大量小 I/O 的场景下,这样的拷贝影响比较大。
鉴于原生 AIO 存在这么多不足之处,于是乎 Jens Axboe(io_uring 作者)就开发出一套全新的异步 I/O 接口来解决这些问题。
既然 io_uring 这么优秀,我们就来学习一下其先进思想吧!下面将会介绍 io_uring 的原理。io_uring 的出现就是为了解决上面的问题,我们来看看 io_uring 是怎么处理的。
1 . 减少系统调用
由于调用系统调用时,会从用户态切换到内核态,从而进行上下文切换,而上下文切换会消耗一定的 CPU 时间。
使用 read() 和 write() 等系统调用进行 I/O 操作时,会从用户态嵌入到内核态,如下图所示:
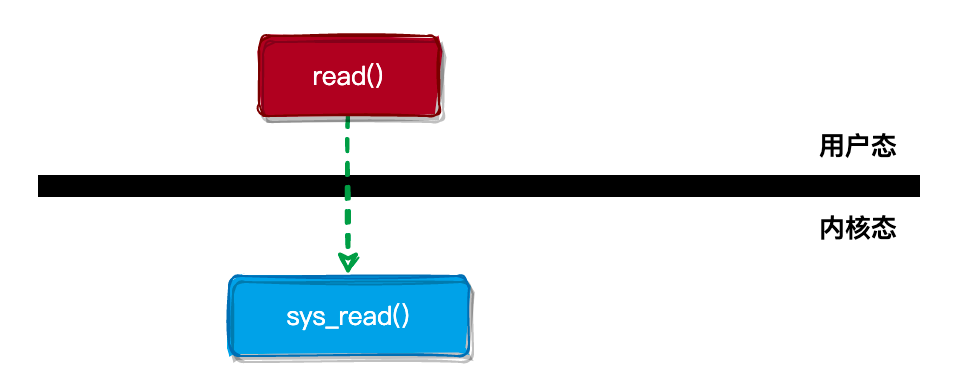
io_uring 为了减少或者摒弃系统调用,采用了用户态与内核态 共享内存 的方式来通信。如下图所示:
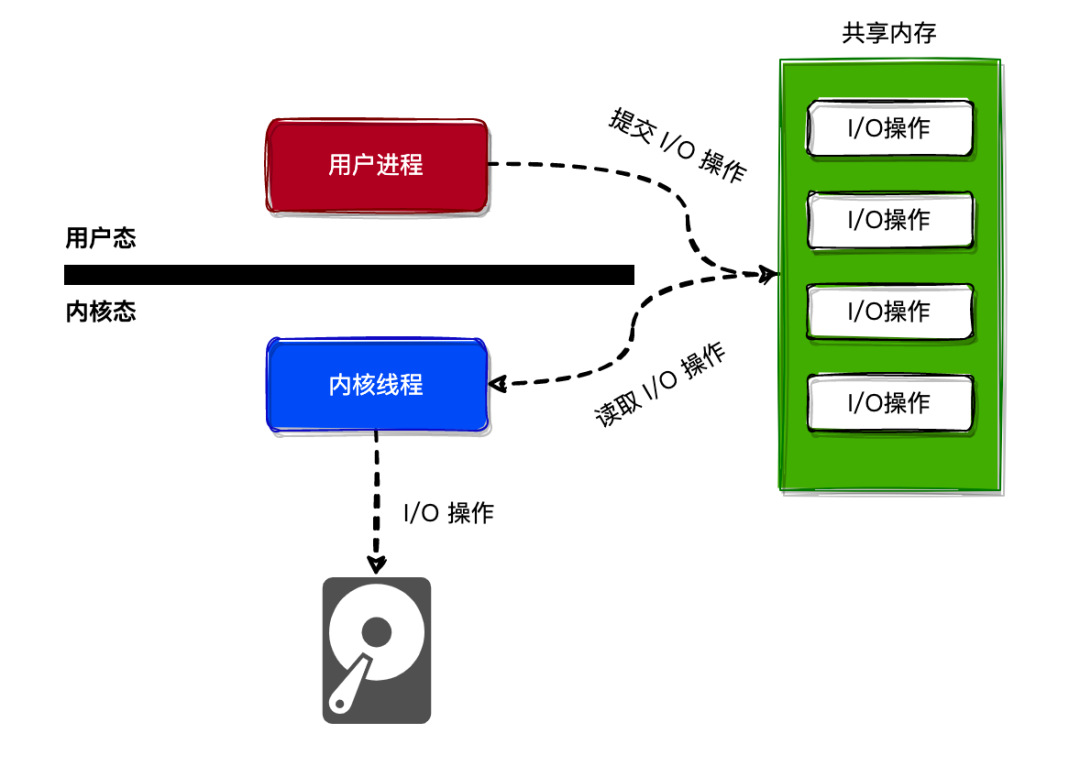
用户进程可以向 共享内存 提交要发起的 I/O 操作,而内核线程可以从 共享内存 中读取 I/O 操作,并且进行相关的 I/O 操作。
用户态对共享内存进行读写操作是不需要使用系统调用的,所以不会发生上下文切换的情况。
2 . 提交队列与完成队列
前面介绍过,io_uring 通过用户态与内核态共享内存的方式,来免去了使用系统调用发起 I/O 操作的过程。
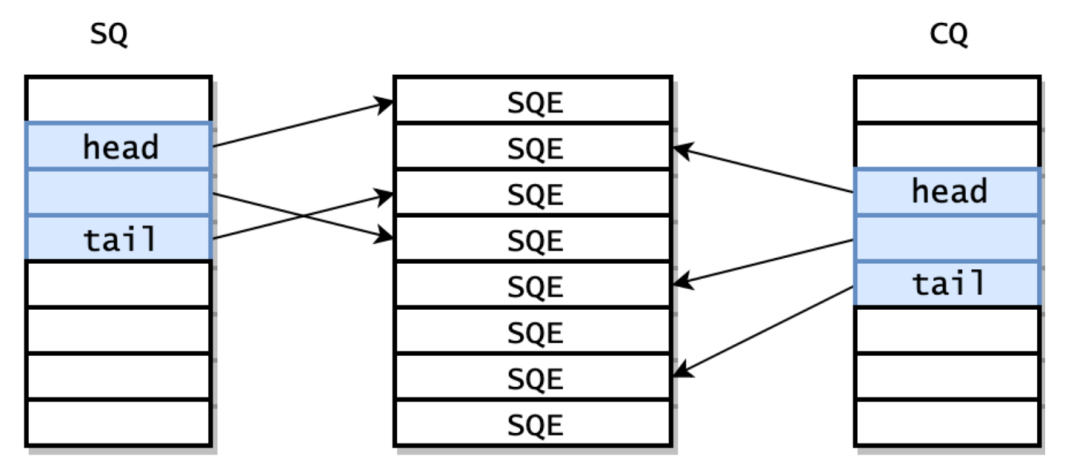
io_uring 主要创建了 3 块共享内存:
- 提交队列(Submission Queue, SQ):一整块连续的内存空间存储的环形队列,用于存放将执行 I/O 操作的数据(指向提交队列项数组的索引)。
- 完成队列(Completion Queue, CQ):一整块连续的内存空间存储的环形队列,用于存放 I/O 操作完成后返回的结果。
- 提交队列项数组(Submission Queue Entry,SQE):提交队列中的一项。
它们之间的关系如下图所示:
提交队列
在内核中,使用 io_sq_ring 结构来表示 提交队列,其定义如下:
struct io_sq_ring {
struct io_uring {
u32 head;
u32 tail;
} r; // 使用head和tail指针来模拟环形操作
...
u32 ring_entries; // 队列中的提交项总数
...
u32 flags;
u32 array[]; // 环形队列数组(指向提交队列项数组的索引)
};io_sq_ring 结构各个字段的含义如下:
- head:环形队列的头指针。
- tail:环形队列的尾指针。
- ring_entries:队列中已存在的 I/O 操作项总数。
- array:环形队列数组,指向提交队列项数组的索引。
io_sq_ring 的结构图如下所示:
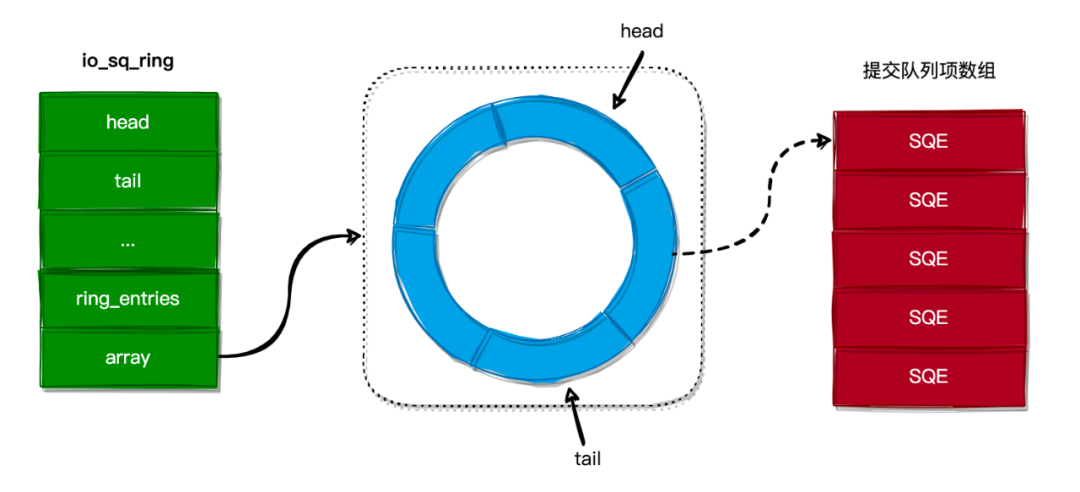
内核会将 io_sq_ring 结构映射到应用程序的内存空间,这样应用程序与内核都能操作 io_sq_ring 结构。应用程序可以直接向 io_sq_ring 结构的环形队列中提交 I/O 操作,而不用通过系统调用来提交,从而避免了上下文切换的发生。
而内核线程可以通过从 io_sq_ring 结构的环形队列中获取到要进行的 I/O 操作,并且发起 I/O 请求。
提交队列项
从上面的分析可知,io_sq_ring 结构 array 字段只是一个整形类型的数组,用于存储指向 提交队列项数组 的的索引。在内核中,提交队列项 使用 io_uring_sqe 结构表示,其定义如下:
struct io_uring_sqe {
__u8 opcode; /* type of operation for this sqe */
...
__u16 ioprio; /* ioprio for the request */
__s32 fd; /* file descriptor to do IO on */
__u64 off; /* offset into file */
__u64 addr; /* pointer to buffer or iovecs */
__u32 len; /* buffer size or number of iovecs */
...
};下面介绍一下 io_uring_sqe 结构各个字段的作用:
- opcode:I/O 操作码,主要用于表示当前的 I/O 操作是什么类型,如读、写或者同步等。
- ioprio:I/O 操作的优先级,可以通过此字段来把一些重要的 I/O 操作提前执行。
- fd:I/O 操作对应的文件句柄。
- off:当前 I/O 操作的偏移量。
- addr:用于指向当前 I/O 操作所关联的内存地址。如写操作,指向的是要写入到文件的内容的内存地址。
- len:表示当前 I/O 操作的数据长度。
当用户调用 io_uring_setup() 系统调用创建一个 io_ring 对象时,内核将会创建一个类型为 io_uring_sqe 结构的数组。内核也会将此数组映射到应用程序的内存空间,这样应用程序就可以直接操作这个数组。
应用程序提交 I/O 操作时,先要从 提交队列项数组 中获取一个空闲的项,然后向此项填充数据(如 I/O 操作码、要进行 I/O 操作的文件句柄等),然后将此项在 提交队列项数组 的索引写入 提交队列 中。
liburing代码库已经把这些繁琐的操作封装成友好的 API,用户只需要直接调用这些 API 来进行操作即可。关于 liburing 代码库的使用,可以参考其使用手册,本文不作详细介绍。
完成队列
当内核完成 I/O 操作后,会将 I/O 操作的结果保存到 完成队列 中。内核使用 io_cq_ring 结构来表示,其定义如下:
struct io_cq_ring {
struct io_uring {
u32 head;
u32 tail;
};
...
u32 ring_entries;
...
struct io_uring_cqe cqes[];
};
struct io_uring_cqe {
__u64 user_data; // 指向 I/O 操作返回的数据
__s32 res; // I/O 操作的结果
...
};完成队列 与 提交队列 类似,也是一个环形队列。下面介绍一下 io_cq_ring 结构各个字段的作用:
- head:环形队列的头指针。
- tail:环形队列的尾指针。
- ring_entries:已完成的 I/O 操作总数。
- cqes:用于保存 I/O 操作结果的环形队列数组,其元素类型为
io_uring_cqe结构。
io_cq_ring 的结构图如下所示:
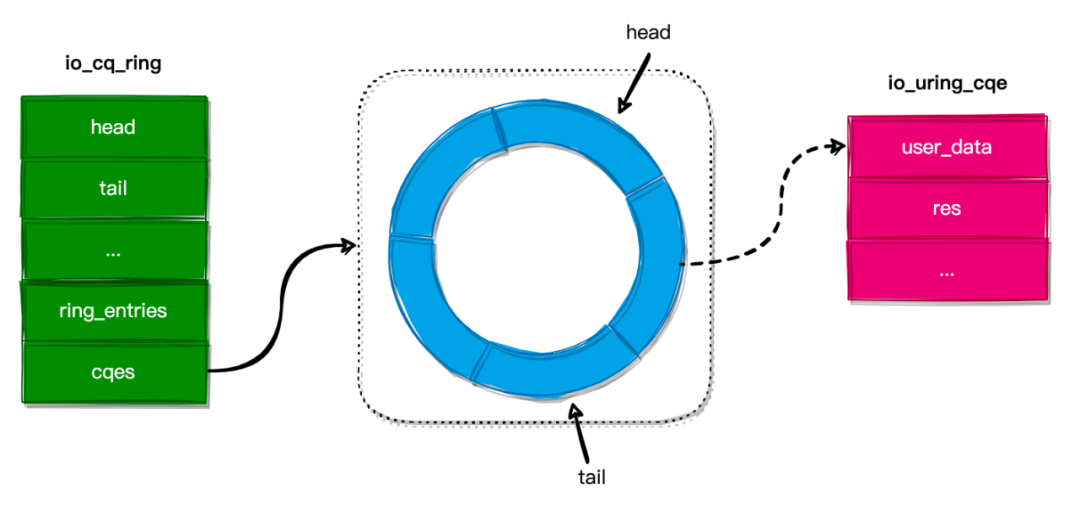
内核也会将 完成队列 映射到应用程序的内存空间,这样应用程序就可以通过读取完成队列来获取 I/O 操作的结果。而不用通过使用系统调用来获取,从而避免了不必要的上下文切换。
3 . SQ 线程
前面介绍了 io_uring 怎么通过共享 提交队列 和 完成队列 来避免不必要的系统调用,但应用程序将 I/O 操作提交到 提交队列 后,内核什么时候从 提交队列 中获取要进行的 I/O 操作,并且发起 I/O 请求呢?
当用户使用 SQPOLL 模式(指定了 IORING_SETUP_SQPOLL 标志)创建 io_uring 时,内核将会创建一个名为 io_uring-sq 的内核线程(称为 SQ 线程),此内核线程会不断从 提交队列 中读取 I/O 操作,并且发起 I/O 请求。
当 I/O 请求完成以后,SQ 线程将会把 I/O 操作的结果写入到 完成队列 中,应用程序就可以从 完成队列 中读取 I/O 操作的结果。
如下图所示:
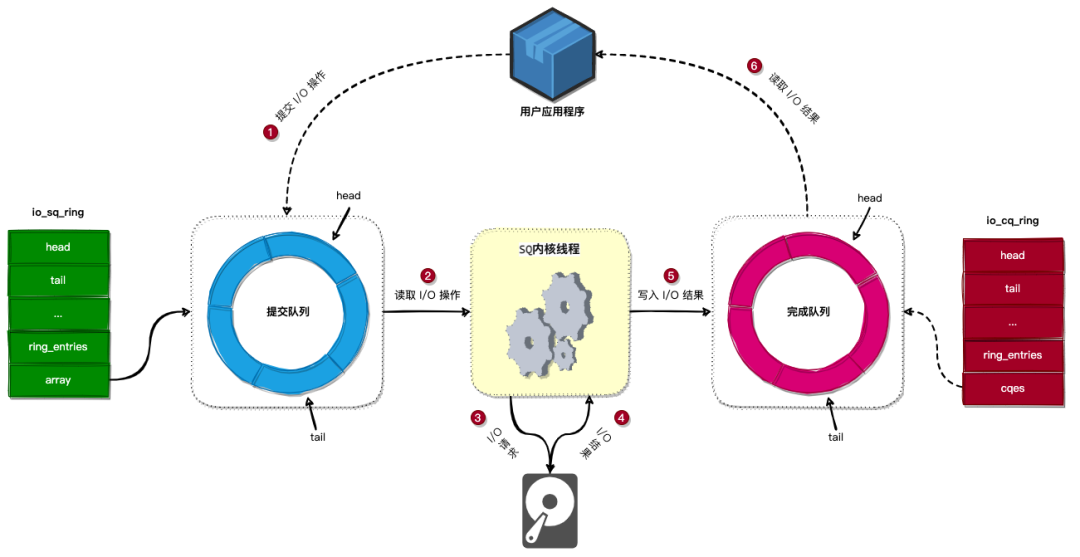
我们简单总结下 io_uring 的操作步骤:
- 第一步:应用程序通过向
io_uring的提交队列提交 I/O 操作。 - 第二步:SQ内核线程从
提交队列中读取 I/O 操作。 - 第三步:SQ内核线程发起 I/O 请求。
- 第四步:I/O 请求完成后,SQ内核线程会将 I/O 请求的结果写入到
io_uring的完成队列中。 - 第五步:应用程序可以通过从
完成队列中读取到 I/O 操作的结果。
4 . 总结
io_uring 主要通过用户态与内核态共享内存的途径,来摒弃使用系统调用来提交 I/O 操作和获取 I/O 操作的结果,从而避免了上下文切换的情况。另外,由于用户态进程与内核态线程通过共享内存的方式通信,从而避免了内存拷贝的过程,提升了 I/O 操作的性能。
所以,io_uring 主要通过两个优化点来提升 I/O 操作的性能:
- 摒弃使用系统调用来提交 I/O 操作和获取 I/O 操作结果。
- 减少用户态与内核态之间的内存拷贝。