这么多年你还在怕正则吗?
前言
不会吧不会吧,这么多年你还在怕正则?这就对了,相信你用不了几分钟看完本文,从此正则算个球。
为啥要用正则表达式
俗话说的好,万事开头难。面对火星文似的正则,就是这样的感觉。那么,我们一起来开个头先。 假设我们需要验证一个字符串是否遵循 8 位数字的电话号码格式:000-12345,该格式前面有 3 位数字,然后紧跟着连字符-,连字符后面再跟着 5 位数字。
不使用正则
function isTelephoneNumber(telephoneNumber) {
if (typeof telephoneNumber !== 'string' || telephoneNumber.length !== 9) {
return false
}
for (let i = 0; i < telephoneNumber.length; i++) {
let c = telephoneNumber[i]
switch (i) {
case 0: case 1: case 2: case 4: case 5:
case 6: case 7: case 8: case 9:
if (c < '0' || c > '9') {
return false
}
break
case 3:
if (c !== '-') {
return false
}
break
}
}
return true
}
复制代码使用正则
function isTelephoneNumber(telephoneNumber) {
return /^\d{3}-\d{5}$/.test(telephoneNumber)
}
复制代码
正则的核心
正则就是匹配模式,要么匹配位置,要么匹配字符。划重点,牢记这个核心。 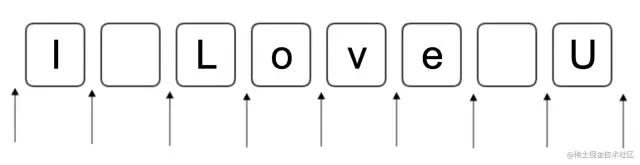
I Love U,箭头就表示我们要匹配的位置,框框里就表示我们要匹配的字符(包括空格)。相信小伙伴们一眼就看明白了。
匹配位置
正则中可以匹配位置的方式如下:
| 模式 | 重要说明 |
|---|---|
| ^ | 匹配开头的位置,当正则有修饰符 m 时(多行文本),表示匹配行开头位置。 |
| $ | 匹配结尾的位置,当正则有修饰符 m 时(多行文本),表示匹配行结尾位置。 |
| \b | 匹配单词边界,即匹配上面示例中的 i、love、U 前后的位置 |
| \B | 匹配非单词边界,与 \b 相反,即匹配上面示例中的 o、v、e 前后的位置 |
| (?=表达式) | 正向先行断言:(?=表达式),指在某个位置的右侧必须能匹配表达式。例如: 给定字符串我爱你 我爱他 我爱 爱你 我和你,匹配右边是“你”的位置。正则可以这么写: /(?=你)/g 如果非要加上“爱”, 如果非要加上“爱”,/爱(?=你)/g,就会匹配出 |
| (?=表达式) | 反向先行断言:(?!表达式),指在某个位置的右侧不能匹配表达式。与 (?=表达式)正好相反。同样是上面的例子:/爱(?!你)/g,就会匹配出 |
| (?=表达式) | 正向后行断言:(?<=表达式),指在某个位置的左侧必须能匹配表达式。注意: 先行断言和后行断言只有一个区别,即先行断言从左往右看,后行断言从右往左看。 |
| (?<!表达式) | 反向后行断言:(?<=表达式),指在某个位置的左侧必须能匹配表达式。 |

test() 方法执行一个检索,用来查看正则表达式与指定的字符串是否匹配。返回 true 或 false。
- 第一题
- 匹配以 javascript 开头的字符串
- 匹配以 javascript 结尾的字符串
/^javascript/.test('javascript is my favorite'); // true
/javascript$/.test('this code in javascript'); // true
复制代码2 . 第二题
仅匹配有边界的
code单词
/\bcode\b/.test('bar code'); // true
/\bcode\b/.test('barcode') // false
复制代码3 . 第三题
匹配姓“李”的名字。
/^李.+/.test('李逍遥'); // true
/^李.+/.test('慕容李逍遥'); // false
// "李" 左侧可以为空格不能为非空格字符
/(?<=[\s]?)(?<!\S)李.+/.test('李逍遥'); // true
复制代码匹配字符
接下来我们看下正则中可以匹配字符的方式:
字符
| 模式 | 说明 |
|---|---|
| 字母、数字 | 匹配字符本身。比如/javascript/,匹配 "javascript";/123/,匹配 "123"。 |
| \0 | 匹配 NUL 字符。 |
| \t | 匹配水平制表符。 |
| \v | 匹配垂直制表符。 |
| \n | 匹配换行符。 |
| \r | 匹配回车符。 |
| \f | 匹配换页符。 |
| \xnn | 匹配拉丁字符。比如 \xOA 等价于 \n。 |
| \uxxxx | 匹配 Unicode 字符。比如 \u2028 匹配行终止符,\u2029 匹配段终止符。 |
| \cX | 匹配 ctrl+X。比如 \cI 匹配 ctrl+I,等价于 \t。 |
| [\b] | 匹配 Backspace 键(特殊记忆)。 |
上面表格内的乍一看特别多,但是别怕,我们记住常见的匹配字母、数字、换行、回车 等等即可。 至此,你已经学废使用正则了,是不是很简单。别高兴的太早,我们还要进阶一下。
字符组
| 模式 | 说明 |
|---|---|
| [abc] | 匹配 "a"、"b"、"c" 其中任何一个字符。 |
| [a-d1-4] | 匹配 "a"、"b"、"c"、"d"、"1"、"2"、"3"、"4" 其中任何一个字符。 |
| [^abc] | 匹配除了 "a"、"b"、"c" 之外的任何一个字符。 |
| [^a-d1-4] | 匹配除了 "a"、"b"、"c"、"d"、"1"、"2"、"3"、"4" 之外的任何一个字符。 |
| . | 通配符,匹配除了少数字符(\n)之外的任意字符。 |
| \d | 匹配数字,等价于 [0-9]。 |
| \D | 匹配非数字,等价于 [^0-9]。 |
| \w | 匹配单词字符,等价于 [a-zA-Z0-9_]。 |
| \W | 匹配非单词字符,等价于 [^a-zA-Z0-9_]。 |
| \s | 匹配空白符,等价于 [ \t\v\n\r\f]。 |
| \S | 匹配非空白符,等价于 [^ \t\v\n\r\f]。 |
[...]字符组语法类似 javascript 中的数组,可能有些小聪明会疑惑。简单的理解就是正则表达式会匹配[...]中的某个字符/表达式,相当于将字符组内的字符遍历匹配。\d \D \w \W \s \S 等都是一些简写,先记个大概以后熟能生巧。接下来看几个实例理解一下。
1 . 第一题
使用字符组匹配 Javascript 和 javascript
const regex = /[Jj]avascript/
regex.test('Javascript'); // true
regex.test('javascript'); // true
复制代码2 . 第二题
匹配“我爱你”或“我想你”或“我”+数字+“你”
const regex = /我[\d爱想]你/
regex.test('我爱你'); // true
regex.test('我想你'); // true
regex.test('我打你'); // false
regex.test('520, 我2你'); // true
复制代码3 . 第三题
匹配爱后面不包含你的数据
/我爱[^你]/.test('我爱你'); // false
复制代码4 . 第四题
匹配数据所有的数字、小写字母和大写字母。
/[a-z0-9A-Z]/.test('b'); // true
/[a-zA-Z\d]/.test('999'); // true
/[a-zA-Z\d]/.test('A'); // true
/[a-zA-Z\d]/.test('A4'); // true
复制代码到目前为止,我们只是学习了关于仅出现一次的字符串匹配,在实际开发中,肯定不能满足需求,比如要匹配电话号码、身份证的时候就无法满足需求了。接下来我们看一下如何匹配多个重复类型的字符
量词
| 模式 | 说明 |
|---|---|
| {n,m} | 连续出现 n 到 m 次。贪婪模式。 |
| {n,} | 至少连续出现 n 次。贪婪模式。 |
| {n,} | 至少连续出现 n 次。贪婪模式。 |
| {n} | 连续出现 n 次。贪婪模式。 |
| + | 等价于 {1,}。贪婪模式。 |
| * | 等价于 {0,}。贪婪模式。 |
| {n,m}? | 连续出现 n 到 m 次。惰性模式。最多匹配到 n 个 |
| {n,}? | 至少连续出现 n 次。惰性模式。最多匹配到 n 个 |
| {n}? | 连续出现 n 次。惰性模式。 |
| ?? | 等价于 {0,1}?。惰性模式。 |
| +? | 等价于 {1,}?。惰性模式。 |
| *? | 等价于 {0,}?。惰性模式。 |
- 贪婪模式――在匹配成功的前提下,尽可能多的去匹配
- 惰性模式――在匹配成功的前提下,尽可能少的去匹配
这是小伙伴们肯定又有点懵逼,我知道你很急,但你先别急。{n,m}简单来说就是需要重复的次数,我们继续来举个栗子。
- 第一题
匹配手机号码,假设手机号码规则如下:
- 必须是 11 位的数字;
- 第一位数字必须以 1 开头,第二位数字可以是 [3,4,5,7,8] 中的任意一个,后面 9 个数是 [0-9] 中的任意一个数字。
const regex = new RegExp(/^1[34578]\d{9}/);
regex.test('18711001111') // true
regex.test('13712345678') // true
regex.test('12345678911') // false
复制代码括号的作用
| 模式 | 说明 |
|---|---|
| (ab) | 捕获型分组。把 "ab" 当成一个整体,比如 (ab)+ 表示 "ab" 至少连续出现一次。 |
| (?:ab) | 非捕获型分组。与 (ab) 的区别是,它不捕获数据。 |
| (good nice) | 捕获型分支结构。匹配 "good" 或 "nice"。 |
| (?:good nice) | 非捕获型分支结构。与 (good nice) 的区别是,它不捕获数据。 |
| \num | 反向引用。比如 \2,表示引用的是第二个括号里的捕获的数据。 |
括号主要是用来分组作用。同样的,我们举个栗子。
1 . 第一题
视频文件的后缀名有 .mp4、.avi、.wmv、.rmvb 用正则表达式提取所有的视频文件的后缀
const regex = new RegExp(/.+(.mp4|.avi|.wmv|.rmvb)/);
regex.exec('海贼王.avi')
// ['海贼王.avi', '.avi', index: 0, input: '海贼王.avi', groups: undefined]
regex.test('朋友.mp3')
// null
regex.test('学习资料.rmvb')
// ['学习资料.rmvb', '.rmvb', index: 0, input: '学习资料.rmvb', groups: undefined]
复制代码正则表达式相关 API
Javascript 中可以通过以下两种方式写正则:
- 正则表达式字面量
- 通过构造函数 RegExp 的实例
例如,创建一个正则用于精确匹配字符串 'test'。
let regExp = /test/
let regExp = new RegExp('test')
// 或者
let regExp = new RegExp(/test/)
复制代码我们还可以在正则上添加一些修饰符,常见的修饰符如下
修饰符
| 模式 | 说明 |
|---|---|
| g | global 简写,全局匹配,找到所有满足匹配的子串,而不是默认只匹配首次结果。 |
| i | ignore case 简写,匹配过程中,忽略英文字母大小写,如 /test/i 可以匹配 Test、teSt、TesT 等。 |
| m | multiline 简写,多行匹配,把 ^ 和 $ 变成行开头和行结尾。比如可以匹配文本域(textarea)元素中的值。 |
| u | unicode 简写,允许使用 Unicode 点转义符。 |
| y | sticky 简写,开启粘连匹配,正则表达式执行粘连匹配时试图从最后一个匹配位置开始。 |
RegExp 相关实例方法
| 模式 | 说明 |
|---|---|
| test[1] | 判断目标字符串中是否有满足正则匹配的子串。返回布尔值。 |
| exec[2] | 比 match[3] 更强大的正则匹配操作。如果正则表达式不包含 g 标志,str.match()[4] 将返回与 RegExp.exec()[5]. 相同的结果。 |
以下是简单的用法,具体用法大伙可以上 mdn 查看相关资料。
new RegExp(/love*/).test('I love you, I love him')
// true
new RegExp(/love*/).exec('I love you, I love him')
// ['love', index: 2, input: 'I love you, I love hime', groups: undefined]
复制代码RegExp 静态属性
| 模式 | 说明 |
|---|---|
| 1,...,1,...,1,...,9 | 最近一次第 1-9 个分组捕获的数据。 |
| input | 最近一次目标字符串,可以简写成 $_ 。 |
| lastMatch | 最近一次匹配的文本,可以简写成 $& 。 |
| lastParen | 最近一次捕获的文本,可以简写成 $+ 。 |
| leftContext | 目标字符串中 lastMatch 之前的文本,可以简写成 $` 。 |
| rightContext | 目标字符串中 lastMatch 之后的文本,可以简写成 $' 。 |
String 相关实例方法
| 模式 | 说明 |
|---|---|
| search[6] | 返回正则匹配到的第一个子串在目标字符串中的下标位置。 |
| split[7] | 以正则匹配到的子串,对目标字符串进行切分。返回一个数组。 |
| match[8] | 对目标字符串执行正则匹配操作,返回的匹配结果数组中包含具体的匹配信息。 |
- groups: 一个命名捕获组对象,其键是捕获组名称,值是捕获组,如果未定义命名捕获组,则为 undefined[9]。有关详细信息,请参阅组和范围[10]。
- index: 匹配的结果的开始位置
- input: 搜索的字符串。 | | replace[11] | 对目标字符串进行替换操作。正则是其第一个参数。返回替换后的字符串。 |
replace 第二个参数中的特殊字符
| 模式 | 说明 |
|---|---|
| 1,1,1,2,...,$99 | 匹配第 1-99 个分组里捕获的文本 |
| $& | 匹配到的子串文本 |
| $` | 匹配到的子串的左边文本 |
| $' | 匹配到的子串的右边文本 |
| $$ | 美元符号 |
replace 第二个参数为函数
你可以指定一个函数作为第二个参数。在这种情况下,当匹配执行后,该函数就会执行。 函数的返回值作为替换字符串。 (注意:上面提到的特殊替换参数在这里不能被使用。) 另外要注意的是,如果第一个参数是正则表达式,并且其为全局匹配模式,那么这个方法将被多次调用,每次匹配都会被调用。
| 变量名 | 代表的值 |
|---|---|
| match | 匹配的子串。(对应于上述的$&。) |
| p1,p2, ... | 假如 replace() 方法的第一个参数是一个RegExp[12] 对象,则代表第 n 个括号匹配的字符串。(对应于上述的1,1,1,2 等。)例如,如果是用 /(\a+)(\b+)/ 这个来匹配,p1 就是匹配的 \a+,p2 就是匹配的 \b+。 |
| offset | 匹配到的子字符串在原字符串中的偏移量。(比如,如果原字符串是 'abcd',匹配到的子字符串是 'bc',那么这个参数将会是 1) |
| string | 被匹配的原字符串。 |
| NamedCaptureGroup | 命名捕获组匹配的对象 |
小试牛刀
第一题
匹配所有符合 XML 规则的标签
const regex = new RegExp(/<(\w+)>.+<\/(\1)>/);
regex.test('<div>code</div>') // true
regex.test('<span>I Love U</span>') // true
regex.test('<h1>This is title</p>') // false
regex.test('<p></p>') // false
复制代码还是比较简单的,主要是用到了括号捕获 <> 中的单词,注意 /为关键字,需要用 \转义。
第二题
请用正则表达式匹配所有的小数
const regex = new RegExp(/(?<!\.)\d+\.\d+$/);
// const regex = new RegExp(/^\d+(?<=\d)\.\d+$/);
regex.test(0.1) // true
regex.test(1.30) // true
regex.test(13.14) // true
regex.test('1.3.1.4') // false
regex.test(1) // false
复制代码(?<!\.)反向后行断言,匹配一个位置其左边不为“.”;接着 \d+\.\d+匹配一位以上的数字 + “.” + 一位以上的数字。
第三题
提取下列数据中所有人的生日,使用两个分组,第一个分组提取“月”,第二个分组提取“日”。 王伟 1993年1月2日 张伟 1996.8.24 李伟 1996.3.21 李秀 1994-7-5
const regex = new RegExp(/((?<=[年.-])\d{1,2})[月.-](\d{1,2}))/);
regex.exec('王伟 1993年1月2日')
// ['1月2', '1', '2', index: 8, input: '王伟 1993年1月2日', groups: undefined]
regex.exec('李伟 1996.3.21')
// ['3.21', '3', '21', index: 8, input: '李伟 1996.3.21', groups: undefined]
复制代码主要还是 (?<=[年.-])反向先行断言,匹配一个位置其左边为 [年.-] 中的一个,其余的就比较容易理解了,最后用 exec 提取捕获组即可。
第四题
编写正则表达式进行密码强度的验证,规则如下:
- 至少一个大写字母
- 至少一个小写字母
- 至少一个数字
- 至少 8 个字符
const regex = new RegExp(/(?=.*?[a-z])(?=.*?[A-Z])(?=.*?[0-9]).{8,}/);
regex.test('123456789') // false
regex.test('12ABab') // false
regex.test('12345ABCabc') // true
regex.test('ADMIN1234()') // false
regex.test('Hmm5201314') // true
复制代码这段正则看着非常长,其实都是重复的逻辑,我们来拆解一下: (?=.*?[a-z]) 这段正则表达式规定了匹配的字符串中必须存在一个右边为任意字符和小写字母的位置,(?=.*?[a-z])(?=.*?[A-Z])(?=.*?[0-9])那这一整串连起来就是必须存在小写、大写、数字。
第五题
实现一个模板引擎,能够满足如下场景使用 let template = '我是{{name}},年龄{{age}},性别{{sex}}'; let data = { name: '姓名', age: 18 } render(template, data); // 我是姓名,年龄18,性别undefined
function render(template, data) {
if(typeof template !== 'string' || typeof data !== 'object') {
return null
}
return template.replace(/{{(.*?)}}/g, (match, $1) => data[$1])
}
复制代码最后这题没啥难度,主要是理解捕获组和字符串的 replace 方法就能解决了。
第六题
写一个方法把下划线命名转成大驼峰命名
function strToCamel(str) {
return str.replace(/(^|_)(\w)/g, (m, $1, $2) => $2.toUpperCase());
}
复制代码同上题,巩固一下凑个数而已 (^0^)。
结束语
老铁们,学废了吗?