在线 AB 实验成为当今互联网公司中必不可少的数据驱动的工具,很多公司把自己的产品来做一次 AB 实验作为数据驱动的试金石。
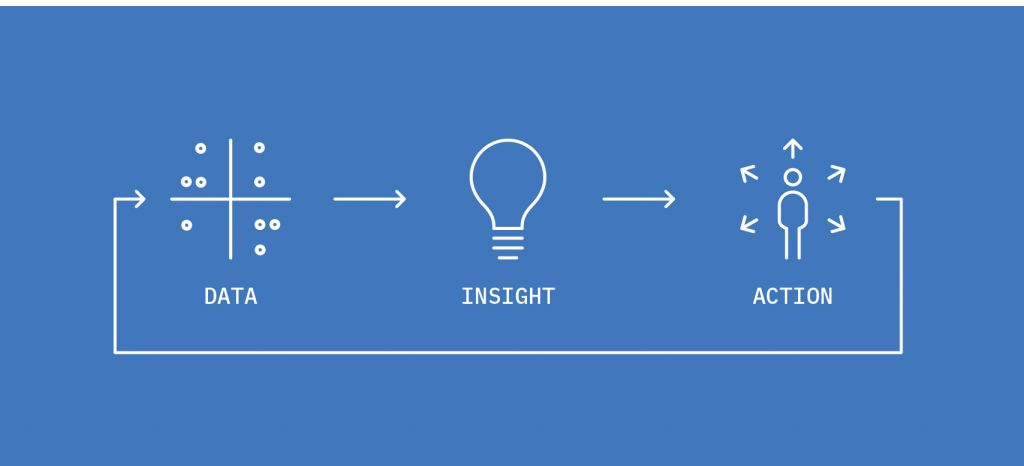
数据 => 洞察 => 优化,循环往复寻找最优解,寻找增长的方法。
AB 中有句经典的名言:大胆假设,小心求证。
本分享从以下几个方面来介绍:
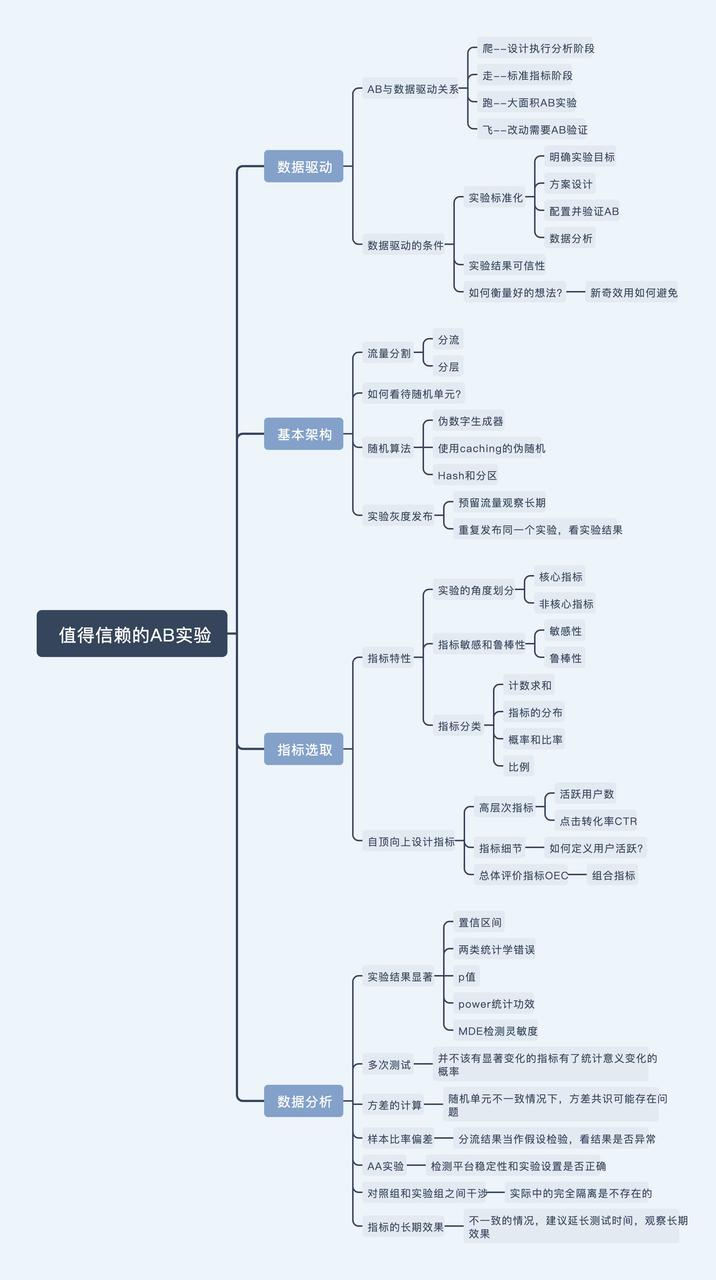
1、数据驱动
2、基本架构
3、指标选取
4、数据分析
AB 实验并不是万能的,没有 AB 实验也不是万万不能,但是有了 AB 实验可以少走很多弯路。
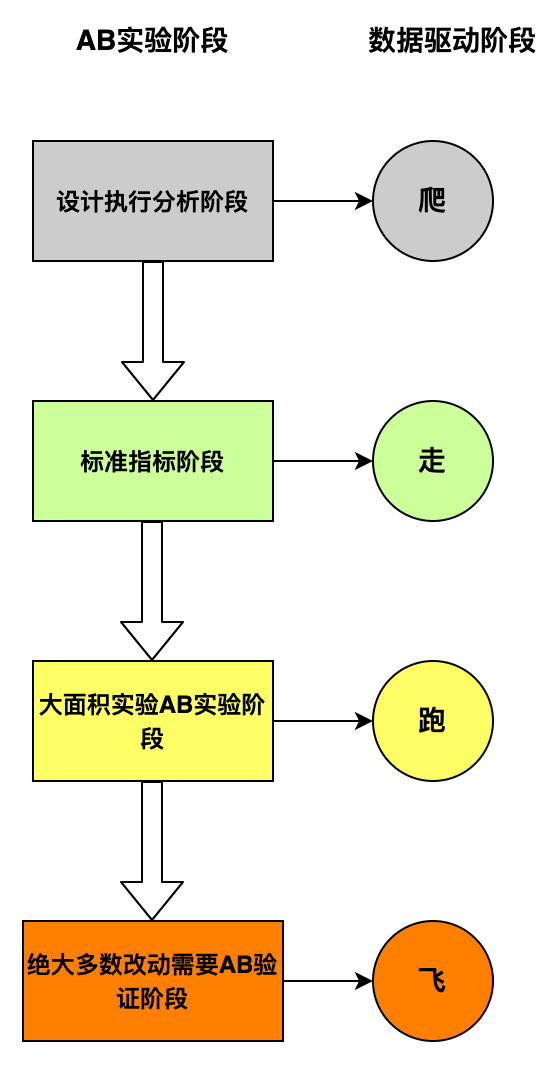
AB 实验阶段对应数据驱动的不同阶段,从最基本的设计执行分析阶段到绝大多数改动需要 AB 验证,从简单到复杂,从少量实验到大规模实验,正好对应的数据驱动从「爬,走,跑,飞」的四个阶段,关系是层层递进的。
设计执行分析阶段主要是:数据检测设置和数据科学能力搭建。在 AB 实验上进行多次的实验,从实验的设计,指标的定义,实验的开启,实验结果的分析,并且找到成功的一些实验案例有助于我们进入到下一阶段。
标准化指标阶段主要是:运行少量实验到定义标准指标再到开启更多实验。AB 实验开始运行更加复杂的 case 来持续验证数据的可行性,并且通过运行 AA 实验来验证平台潜在的问题,同时能够进行样本比率偏差检测。
从上一个阶段的标准化指标,已经可以运行大量实验,并且各种指标也逐渐相对成熟,每次实验进行多个指标的权衡,然后在一个应用上利用 AB 实验对绝大多数的新功能和改动做实验。
几乎所有的改动都需要经过 AB 实验的验证,可以在没有数据科学家的辅助下,可以对大多数的实验进行独立的分析和运作。同时通过对过去实验的分析,AB 实验的有效性和最佳实践也能得到不断的更新。
数据决策肯定是一套标准化的东西来规范,实验标准化也是 AB 数据驱动的必备条件。
那什么是 AB 实验的标准化呢?
AB 实验需要注意⚠️辛普森悖论、幸存者偏差、选择偏差等,注意事项都是来源于对撞因子,简单来说就是「是指同时被两个以上的变数影响的变数」,具体的可以在 google 深入了解一下。
有数字容易,让人信赖的数字需要下功夫。开启实验容易,实验报告有数字很容易,这些数字的可信度,这些数字让人信赖更重要,需要花费更长的时间。
大量实验中可能只有很小一部分实验,例如微软大约 30% 的结果是正向积极的,最终可以发布到整个应用上。
举个例子:
如果我抛起三枚硬币,落地分别是正正反,那么我可以说抛硬币正面朝上的概率是三分之二吗?
概率和频率并不是一个东西,同理,少数几次 AB 实验的结果也不能证明版本 A 和版本 B 的优劣。
我们需要统计学上的严格论证和计算,来判断一个实验结果是否显著,是否可信。
对于任何一个想法我们很难去衡量它的好坏,大胆假设小心求证。短期目标可能会与更关键的长期目标发生冲突。
举个例子:
一家超市突然提高价格,可能会在短期带来更高利润。但长远看,如果更多的顾客改从竞争对手那里购买商品,那么这家店的收入就会减少。
新奇效应如何避免?
对于用户有感知的 A/B Test,如 UI 改版、新的运营方案、新功能上线等,实验组做的任何改变都可能引起用户的注意,好奇心驱使他们先体验一番,从而导致 A/B Test 中实验组效果一开始优于对照组,p-value 极小,实验效果非常显著。但是一段时间过去后,用户对于新的改版不再敏感,实验组效果回落,显著性可能会下降,最后趋于稳定。足够的样本量能保证一个合理的实验周期,可以使用我们的流量计算器中计算流量和实验周期,从而避免这种新奇效应的影响。
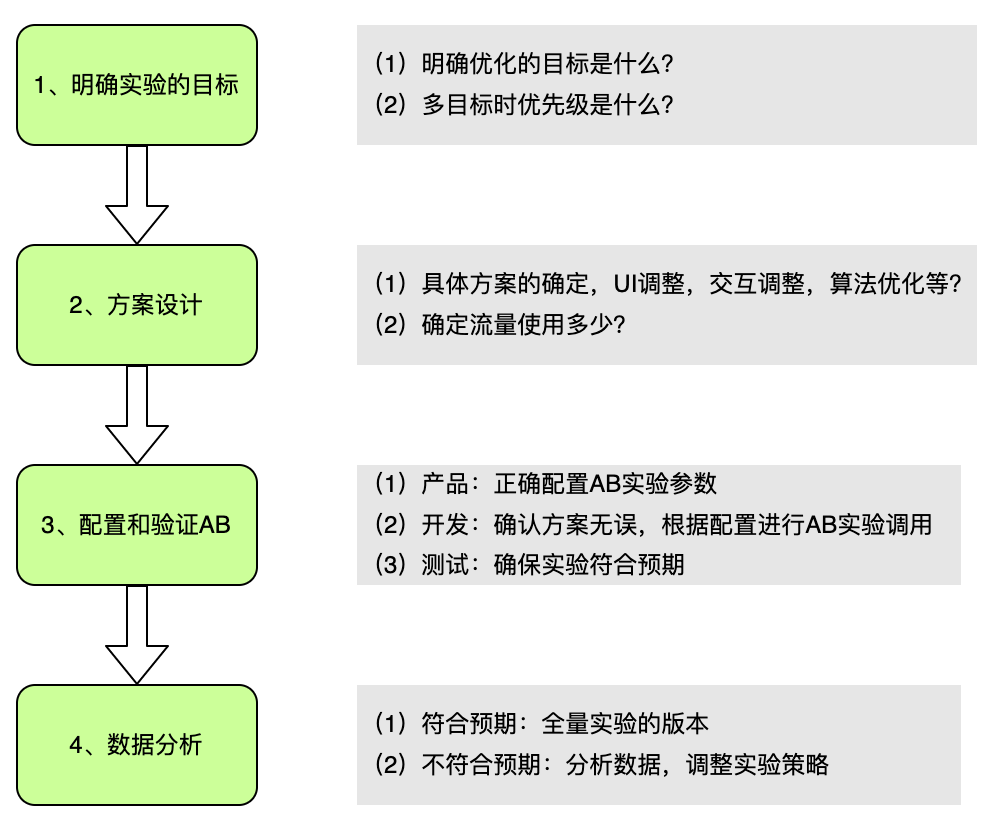
AB 实验的思想非常简单直观,但是并不是代表做 AB 实验是一种很简单容易的事情。
举个例子,在网站实现一个 AB 实验,主要涉及到 2 分部分:
第 1 个是:随机算法,作用是将 users 映射到不同实验组中。
第 2 个是:分配方法,随机算法的结果来决定每一个用户是否看到该网站的实验。
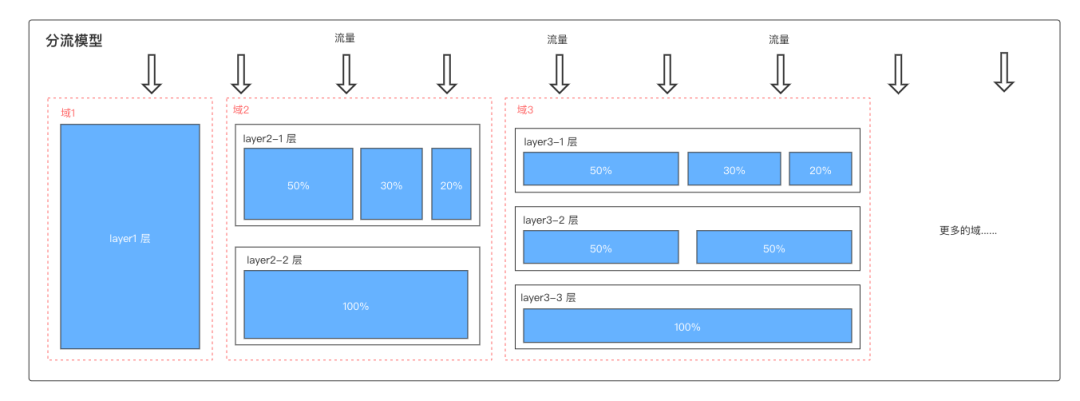
流量分割的方式:分流和分层。
每个独立实验为一层,层与层之间流量是正交的(简单来讲,就是一份流量穿越每层实验时,都会再次随机打散,且随机效果离散)。实验在同一层拆分流量,不论如何拆分,不同组的流量是不重叠的。
分流是指我们直接将整体用户切割为几块,用户只能在一个实验中。但是这种情况很不现实,因为如果我要同时上线多个实验,流量不够切怎么办?那为了达到最小样本量,我们就得延长实验周期,要是做一个实验,要几个月。
简单来说:分流是指对流量进行整体切割,实验之间互斥。
目的:为了获取纯净的分区,不会互相影响。
缺点:浪费流量,导致流量不够。
就是将同一批用户,不停的随机后,处于不同的桶。也就是说,一个用户会处于多个实验中,只要实验之间不相互影响,我们就能够无限次的切割用户。这样在保证了每个实验都能用全流量切割的同时,也保证了实验数据是置信的。
简单来说:对整体流量分流分层。
目的:同一个用户在不同的实验组,相互不会影响。
缺点:不同层之间的 hash 值尽量不要重合。
什么是随机单元呢?简单来说,随机单元就是 AB 实验需要达到随机的最小单元。一个 web 网站中,最小单元可能是页面级别,可能是会话级别,或者是用户级别。
举个例子:
我们选择页面级别的随机单元,AB 实验针对某一个页面,用户每一次打开页面的时候决定把该用户导向某一个实验组。
最简单的情况就是:随机单元和分析单元是一致的。我们大多数情况也是将随机单元和分析单元采用用户级别。两种单元不一致可能使得实验分析变得更加复杂。
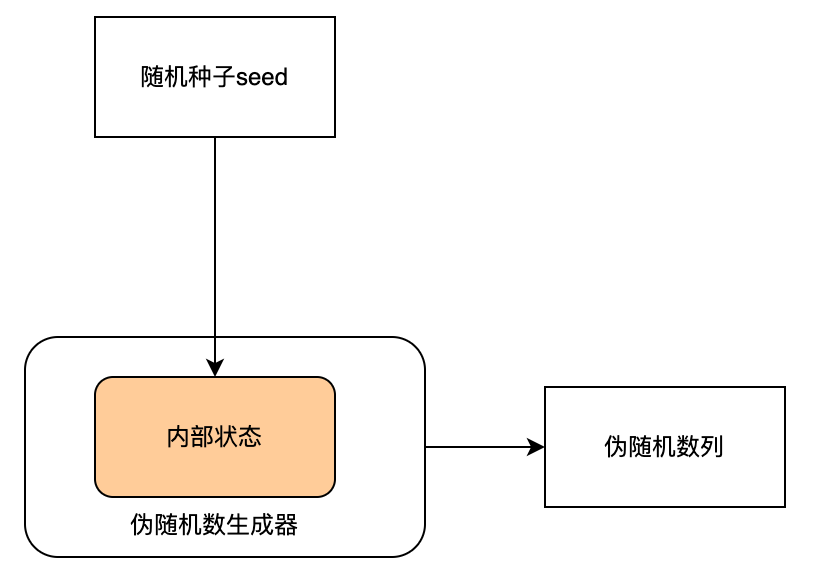
首先什么是随机数?不确定的数。
大多数随机算法使用的是伪数字生成器。
那什么是伪数字生成器?一个生产数字序列的算法,特征近似随机数序列的特性。伪随机数生成器通常接受一个随机种子(seed) 用来初始化生成器的初始状态。
按照密码学来将「随机」分为三种级别:
1. 伪随机 (PRNG) 2. 密码学安全的伪随机 (CSPRNG) 3. 真随机 (TRNG)
伪随机 PRNG 生成的序列并不是真随机。它完全是由一个初始值决定,初始值称为随机种子(seed)。接近于真随机序列可以通过硬件随机数生成器生成。但是伪随机数生成器因为其生成速度和可再现的优势,实践中也很重要。
寻找一个合适的随机算法是非常重要的。
一个实验的每一个 variant (实验组或对照组)都具有关于 users 的一个随机抽样。随机算法必须有一些特征。特征如下:
伪随机数的随机性可以用它的统计特性来衡量,主要特征是每个数出现的可能性和它出现时与数序中其他数的关系。
伪随机数的优点是它的计算比较简单,而且只使用少数的数值很难推断出它的计算算法。
使用 caching 缓存,可以使用标准伪数字生成器作为随机算法,一个好的伪数字生成器会满足特征(1)和特征(3)。
对于特征(2),需要引入状态,用户的分配必须被缓存,或者缓存完成可以是数据库存储,便于下次再次访问应用。
不同于伪随机方法,hash 和分区是无状态的,每一个 user 都会被分配一个唯一的 user_unique_id,使用 ssid 和 webid (或者其他)来维持。user_unique_id 会和实验的 id 进行映射绑定,接着 user_unique_id 和实验 id 使用 hash 函数来获得一个整数,整数的范围是均匀分布的。
hash 函数的选取需要注意⚠️,如果 hash 函数有漏斗(那些相邻 key 的实例会映射到相同的 hash code),会造成均匀分布的冲突,如果 hash 函数有特性(某一个 key 变动会产生一个 hash code 上可预测的变动),会造成实验之间会发生相关。
「加密 hash 函数 MD5 」生成的数据在实验间没有相关性。其实还可以关注「大质数素数 hash 算法」等更加精密优良的算法。
实验发布是一个容易忽略但又非常重要的步骤,从比较小的流量慢慢发布到相对比较大的流量,直到最后全站发布。这个过程是需要自动化和风险控制相结合。
我们经常的做法就是:
选取什么指标来进行检测,从而更好的帮助我们进行数据驱动决策。
对于一个应用或者产品来说,可能会有很多指标的选择,哪些指标需要被重点关注,哪些仅仅是关注,哪些是可以不关注。为什么要定义这个指标,这个指标的定义是为了说明什么情况,如果这个指标发生变化,将需要怎么去解释它。
选取什么指标来进行检测,从而更好的帮助我们进行数据驱动决策。
对于一个应用或者产品来说,可能会有很多指标的选择,哪些指标需要被重点关注,哪些仅仅是关注,哪些是可以不关注。为什么要定义这个指标,这个指标的定义是为了说明什么情况,如果这个指标发生变化,将需要怎么去解释它。
核心指标:需要优化的目标指标,决定这个实验的最终发展方向。这种指标在一个实验是非常少的,在运行之后是不做改变的。
非核心指标指标:与核心指标有因果关系的+基础数据的指标,基础数据的指标是应用运行的底线。
指标敏感性:指标对所关心的事物是否足够敏感。
指标鲁棒性:指标对不关心的事物是否足够不敏感。
可以通过预先小规模试验来验证,或者 AA 试验来排除伪关系。
(1)计数或者求和(比如:访问页面的用户数)。
(2)指标分布的平均数,中位数,百分位。
(3)概率与比率。
(4)比例。
(1)高层次的指标(比如:活跃用户数,点击转化率 CTR 等等)。
(2)指标细节(比如:如何定义用户活跃)。
(3)使用一组指标,并将它们整合成一个单一指标(比如:总体评价指标 OEC )。
总体评价指标 OEC :如果是使用一套指标,可以把他们聚合成一个指标,比如构造一个目标函数,或者是简单的加权指标。比如 OEC = A * 0.6 + B * 04 + C * 2 。
现在我们的策略是指标,还是独立去观测。那为啥不使用 OEC 来看指标呢?通过 OEC 看的指标不能单独观测多个指标,对于新手小白比较友好,只需要关注 OEC,不需要关注多个指标的数据,但是并不能真的反应多个指标的真实情况。
举个例子:
点击率的定义:
有了 AB 实验,并且有实验指标选取之后,实验结果的分析就成为一件非常重要而且有挑战的事情。
产生一组数据很容易,但是从数据中分析得到实验的洞察(Insight)并不简单。
上面有说到实验结果的可信度,接下来详细来介绍。
说到实验结果是否显著,我们需要知道统计学中 2 类统计错误,我们简单说明一下,这里我们不展开说。
在统计学的世界里,我们往往只说概率,不说确定,在现实世界中往往只能基于样本进行推断。在 AB 实验中,我们 不知道真实情况是什么,因此做假设检验的时候就会犯错误,这种错误可以划分为两类:
理想状态下当然是希望可以同时控制这两类错误,但是这是不可能的,两个概率值之间是负向关系,其中一个值的减少必然伴随着另一个值的增大,为什么呢?后续有机会再分享。
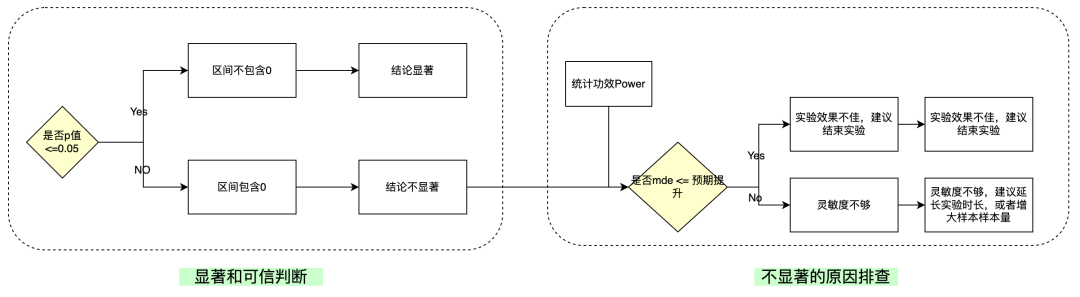
是否显著,是否可信,我们可以通过以下几种因素来判断:
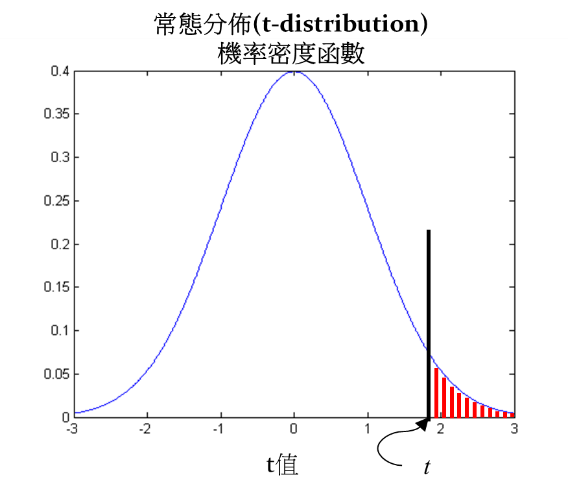
(1)p 值。展示该指标在实验中犯第一类错误的概率,该概率小于显著性水平 α ,统计学中称为显著, 1-α 为置信度或置信水平。
通常情况下:
p 值 > α(显著水平α,α 值一般 5%) ,说明 A 版本和 B 版本没有太大差别,不存在显著性差异。
p 值 < α(显著水平,α 值一般 5%),说明 A 版本和 B 版本有很大的差别,存在显著性差异。
我们根据判断 p 值和第一类错误概率 α 比较,已经做了决策。是不是觉得大功告成,不,我们可以继续考虑 power 统计功效来衡量实验的可信。也就是我们要同时考虑第二类错误概率,这时候引入 power 统计功效。
(2)power 统计功效(1 - )。实验能正确做出存在差异判断的概率。
举个例子:
实验 A 显示,power(统计功效)为 92%,那么就可以理解为有 92% 的把握认为版本 A 和版本 B 之间是有差别的。
但是 power 根本算不出来,power 作为需要满足的前提条件,作为先验的输入值。
(3)MDE 检验灵敏度,能有效检验出指标置信度的 diff 幅度。
通过比较指标 MDE 与指标的目标提升率来 判断不显著的结论是否 solid,可以避免实验在灵敏度不足的情况下被过早作出非显著结论而结束,错失有潜力的 feature。
MDE 越小,说明当前的实验灵敏度越高, 并且可以认为:实验组相比于对照组,只有高于 MDE 的提升才能大概率检测出效果显著。小于 MDE 的提升,大概率不会被检测出显著。
举个例子
假设你对该指标的预期目标提升率为 1%。
(4)置信区间。置信区间就是用来对一个概率样本的总体参数的进行区间估计的样本均值范围。一般来说,我们使用 95% 的置信水平来进行区间估计。
置信区间可以辅助确定版本间是否有存在显著差异的可能性:
在火山引擎 AB 测试的实验报告中,指标分析的详细视图中有个值叫相对差,该值就是指标变化的点估计值,而置信区间给出的是指标预期变化的区间估计**值,**区间估计值有更大的可能性覆盖到指标相对变化的真实值。(假设做 100 次实验,有 95 次算出的置信区间包含了真实值)。
可以这样简单但不严谨地解读置信区间 :假设策略全量上线,你有 95% 的把握会看到真实的指标收益在 置信区间 这个范围内。
5.1.3 决策流程
简单的说:传统的假设检验的设置是对需要检测的「假设」进行唯一测试,然后计算 p 值。我们有 5% 的概率观测到某一个并没有实际变化的“指标”显得有统计意义上的显著变化。
现实中,对于同一个实验,我们通过 AB 实验反复观察结果,或者反复针对同一个想法进行迭代。
出现更严重的问题就是:我们针对同一个实验,常常同时观测几十个或者上百个指标,导致出现多次实验的问题,大大增加了观测并不该有显著变化的指标有了统计意义变化的概率。
t检测中我们需要对数据的方法进行计算。有时候我们的“方差”计算是有问题的,之前有说到的「随机单元」和「分析单元」不一致的情况下,计算比率型的指标,比如点击率。
我们来看一个场景:经常我们的「随机单元」是用户级别的,然而我们希望计算的是一些页面级别的点击率,然后看对照组和实验组之间的差别的,这个时候就存在「随机单元」和「分析单元」不一致的问题,传统的计算点击率的「方差」公式可能存在问题。
在理想的状态下,对照组和实验组的流量是一半一半的,也就是 50% 的进入到对照组,50% 的进入到实验组。但是现实是残酷的,比如会出现 50.27% 的用户进入到对照组,另外 49.73% 的用户进入到实验组。
这种情况正常吗?我们还信任这样的实验结果吗?
这样情况的排查和分析。简单的说,我们需要把这样的分流结果当作假设检验,看这样的结果是否异常。
AA 实验往往作为检测平台稳定性和实验设置是否正确的重要手段。
总是有人想着做「AA」实验,为什么会这样呢?说到底还是对于 AB 实验存在疑虑和不信赖。大多数想做 AA 实验的目的主要是:验证用户分流是否“均匀”;比较“ AA 组内差异”和“ AB 组间差异”。
其实 AA 实验中的指标差异显著/置信并不代表分流不科学,AA 实验的指标必然存在差异,并且指标差异可能还不小,AA 差异可能“显著”。
也就是说,对 AB 系统本身进行测试,以确保系统在 95% 的时间内正确识别出没有统计学意义上的显著差异。
传统的实验我们假设对照组和实验组是完全隔绝的,然后实际中,完全的隔离是不可能的。
举个例子:
社招网络中,朋友与朋友的关系,我们按照传统的随机划分流量的方法,可能一个用户在对照组,他的朋友在实验组,这样这个用户可能接触到对照组的一些信息,从而违背了假设检验的一系列基本假设。
有一些“指标”的效果在 A/B 实验之后,可能会出现一些“恶化”,也就是说,效果可能没有之前那么明显了,甚至会出现效果完全消失。
如果遇到短期效果与长期效果可能出现不一致的情况,建议延长测试时间,观察长期效果。
但是长期存在一些问题:
(1)用户唯一标识(比如:ssid)跳变的情况,进行实验时候,通过随机分配的 ssid,进行确定用户身份,但是用户可以在浏览器中修改 localstorage 中的 ssid,保持一个稳定的样本几乎不可能,实验进行的越久,问题越严重。
(2)幸存者偏差的情况,过度关注幸存者,忽略没有幸存的而造成错误结论。
(3)选择偏差的情况,由于 ssid 跳变,只有登陆的用户组成,不具备代表性。
本文由哈喽比特于1年以前收录,如有侵权请联系我们。
文章来源:https://mp.weixin.qq.com/s/2sE-KxdRAvnp3GBOBU4Cfg
京东创始人刘强东和其妻子章泽天最近成为了互联网舆论关注的焦点。有关他们“移民美国”和在美国购买豪宅的传言在互联网上广泛传播。然而,京东官方通过微博发言人发布的消息澄清了这些传言,称这些言论纯属虚假信息和蓄意捏造。
日前,据博主“@超能数码君老周”爆料,国内三大运营商中国移动、中国电信和中国联通预计将集体采购百万台规模的华为Mate60系列手机。
据报道,荷兰半导体设备公司ASML正看到美国对华遏制政策的负面影响。阿斯麦(ASML)CEO彼得·温宁克在一档电视节目中分享了他对中国大陆问题以及该公司面临的出口管制和保护主义的看法。彼得曾在多个场合表达了他对出口管制以及中荷经济关系的担忧。
今年早些时候,抖音悄然上线了一款名为“青桃”的 App,Slogan 为“看见你的热爱”,根据应用介绍可知,“青桃”是一个属于年轻人的兴趣知识视频平台,由抖音官方出品的中长视频关联版本,整体风格有些类似B站。
日前,威马汽车首席数据官梅松林转发了一份“世界各国地区拥车率排行榜”,同时,他发文表示:中国汽车普及率低于非洲国家尼日利亚,每百户家庭仅17户有车。意大利世界排名第一,每十户中九户有车。
近日,一项新的研究发现,维生素 C 和 E 等抗氧化剂会激活一种机制,刺激癌症肿瘤中新血管的生长,帮助它们生长和扩散。
据媒体援引消息人士报道,苹果公司正在测试使用3D打印技术来生产其智能手表的钢质底盘。消息传出后,3D系统一度大涨超10%,不过截至周三收盘,该股涨幅回落至2%以内。
9月2日,坐拥千万粉丝的网红主播“秀才”账号被封禁,在社交媒体平台上引发热议。平台相关负责人表示,“秀才”账号违反平台相关规定,已封禁。据知情人士透露,秀才近期被举报存在违法行为,这可能是他被封禁的部分原因。据悉,“秀才”年龄39岁,是安徽省亳州市蒙城县人,抖音网红,粉丝数量超1200万。他曾被称为“中老年...
9月3日消息,亚马逊的一些股东,包括持有该公司股票的一家养老基金,日前对亚马逊、其创始人贝索斯和其董事会提起诉讼,指控他们在为 Project Kuiper 卫星星座项目购买发射服务时“违反了信义义务”。
据消息,为推广自家应用,苹果现推出了一个名为“Apps by Apple”的网站,展示了苹果为旗下产品(如 iPhone、iPad、Apple Watch、Mac 和 Apple TV)开发的各种应用程序。
特斯拉本周在美国大幅下调Model S和X售价,引发了该公司一些最坚定支持者的不满。知名特斯拉多头、未来基金(Future Fund)管理合伙人加里·布莱克发帖称,降价是一种“短期麻醉剂”,会让潜在客户等待进一步降价。
据外媒9月2日报道,荷兰半导体设备制造商阿斯麦称,尽管荷兰政府颁布的半导体设备出口管制新规9月正式生效,但该公司已获得在2023年底以前向中国运送受限制芯片制造机器的许可。
近日,根据美国证券交易委员会的文件显示,苹果卫星服务提供商 Globalstar 近期向马斯克旗下的 SpaceX 支付 6400 万美元(约 4.65 亿元人民币)。用于在 2023-2025 年期间,发射卫星,进一步扩展苹果 iPhone 系列的 SOS 卫星服务。
据报道,马斯克旗下社交平台𝕏(推特)日前调整了隐私政策,允许 𝕏 使用用户发布的信息来训练其人工智能(AI)模型。新的隐私政策将于 9 月 29 日生效。新政策规定,𝕏可能会使用所收集到的平台信息和公开可用的信息,来帮助训练 𝕏 的机器学习或人工智能模型。
9月2日,荣耀CEO赵明在采访中谈及华为手机回归时表示,替老同事们高兴,觉得手机行业,由于华为的回归,让竞争充满了更多的可能性和更多的魅力,对行业来说也是件好事。
《自然》30日发表的一篇论文报道了一个名为Swift的人工智能(AI)系统,该系统驾驶无人机的能力可在真实世界中一对一冠军赛里战胜人类对手。
近日,非营利组织纽约真菌学会(NYMS)发出警告,表示亚马逊为代表的电商平台上,充斥着各种AI生成的蘑菇觅食科普书籍,其中存在诸多错误。
社交媒体平台𝕏(原推特)新隐私政策提到:“在您同意的情况下,我们可能出于安全、安保和身份识别目的收集和使用您的生物识别信息。”
2023年德国柏林消费电子展上,各大企业都带来了最新的理念和产品,而高端化、本土化的中国产品正在不断吸引欧洲等国际市场的目光。
罗永浩日前在直播中吐槽苹果即将推出的 iPhone 新品,具体内容为:“以我对我‘子公司’的了解,我认为 iPhone 15 跟 iPhone 14 不会有什么区别的,除了序(列)号变了,这个‘不要脸’的东西,这个‘臭厨子’。